# ChatGPT Resources
## Public Info
+ [Blog Post](https://openai.com/blog/chatgpt/)
> ChatGPT is a sibling model to **InstructGPT**, which is trained to follow an instruction in a prompt and provide a detailed response. We trained this model using **Reinforcement Learning from Human Feedback (RLHF)**, using the same methods as InstructGPT, but with slight differences in the data collection setup. ChatGPT is fine-tuned from a model in the **GPT-3.5** series
`text-davinci-003 is an improvement on text-davinci-002`
 ## Business Context
+ [OpenAI in 2019](https://vicki.substack.com/p/i-spent-1-billion-and-all-i-got-was)
## High-level overview:
+ [OpenGPT Jailbreak?](https://www.youtube.com/watch?v=0A8ljAkdFtg)
## Training Data
## Business Context
+ [OpenAI in 2019](https://vicki.substack.com/p/i-spent-1-billion-and-all-i-got-was)
## High-level overview:
+ [OpenGPT Jailbreak?](https://www.youtube.com/watch?v=0A8ljAkdFtg)
## Training Data
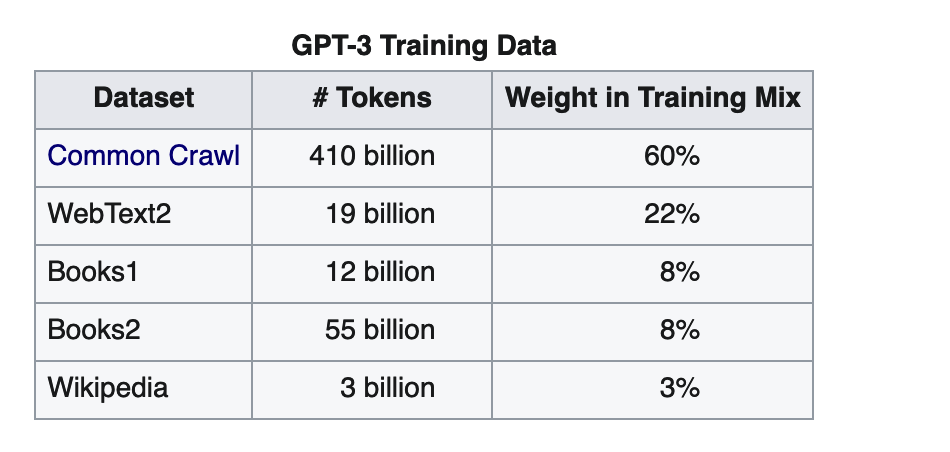 The model was trained on
+ Books1
+ Books2
+ [Common Crawl](https://en.wikipedia.org/wiki/Common_Crawl)
+ WebText2
+ [My Twitter Thread Question on Training Data](https://twitter.com/vboykis/status/1290030614410702848)
+ [Books1 and Books2](https://twitter.com/theshawwn/status/1320282151645073408) - [Books1 Resources](https://github.com/soskek/bookcorpus/issues/27#issuecomment-716104208)
+ [Bookcorpus paper](https://arxiv.org/abs/2105.05241)
+ [What's in MyAI Paper](https://lifearchitect.ai/whats-in-my-ai-paper/), [Source](https://twitter.com/kdamica/status/1600328844753240065)
+ The model data is recent as of 2021 and does offline inference :
The model was trained on
+ Books1
+ Books2
+ [Common Crawl](https://en.wikipedia.org/wiki/Common_Crawl)
+ WebText2
+ [My Twitter Thread Question on Training Data](https://twitter.com/vboykis/status/1290030614410702848)
+ [Books1 and Books2](https://twitter.com/theshawwn/status/1320282151645073408) - [Books1 Resources](https://github.com/soskek/bookcorpus/issues/27#issuecomment-716104208)
+ [Bookcorpus paper](https://arxiv.org/abs/2105.05241)
+ [What's in MyAI Paper](https://lifearchitect.ai/whats-in-my-ai-paper/), [Source](https://twitter.com/kdamica/status/1600328844753240065)
+ The model data is recent as of 2021 and does offline inference :
 ## Models
+ My Twitter Thread Question [on the Model](https://twitter.com/vboykis/status/1600307649496522753)
+ [Language Models are Few-Shot Learners: GPT3](https://arxiv.org/abs/2005.14165)
+ [Model- reinforcement learning for language models](https://github.com/lvwerra/trl)
+ [Illutstrating Reinforcement Learning from Human Feedback Tutorial](https://huggingface.co/blog/rlhf)
+ ChatGPT is actually three models in a trench coat: a language model, a reward model, and fine-tuning the langauge model with a reward model
+ [InstructGPT Blog Post](https://openai.com/blog/instruction-following/)
+ [InstructGPT Model Card](https://github.com/openai/following-instructions-human-feedback/blob/main/model-card.md)
+ [Models Referred to as GPT 3.5](https://beta.openai.com/docs/model-index-for-researchers)
+ [OpenAI comes clean about GPT 3.5](https://jmcdonnell.substack.com/p/openai-comes-clean-about-gpt-35)
+ [Possibly davinci-003](https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse)
## Model Evaluation
+
## Market
+ [OpenAI models as a service](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models)
## Models
+ My Twitter Thread Question [on the Model](https://twitter.com/vboykis/status/1600307649496522753)
+ [Language Models are Few-Shot Learners: GPT3](https://arxiv.org/abs/2005.14165)
+ [Model- reinforcement learning for language models](https://github.com/lvwerra/trl)
+ [Illutstrating Reinforcement Learning from Human Feedback Tutorial](https://huggingface.co/blog/rlhf)
+ ChatGPT is actually three models in a trench coat: a language model, a reward model, and fine-tuning the langauge model with a reward model
+ [InstructGPT Blog Post](https://openai.com/blog/instruction-following/)
+ [InstructGPT Model Card](https://github.com/openai/following-instructions-human-feedback/blob/main/model-card.md)
+ [Models Referred to as GPT 3.5](https://beta.openai.com/docs/model-index-for-researchers)
+ [OpenAI comes clean about GPT 3.5](https://jmcdonnell.substack.com/p/openai-comes-clean-about-gpt-35)
+ [Possibly davinci-003](https://www.lesswrong.com/posts/t9svvNPNmFf5Qa3TA/mysteries-of-mode-collapse)
## Model Evaluation
+
## Market
+ [OpenAI models as a service](https://learn.microsoft.com/en-us/azure/cognitive-services/openai/concepts/models)
 ## Infra
+ Azure
+ [K8s](https://openai.com/blog/scaling-kubernetes-to-7500-nodes/) [Source here](https://jawns.club/@april@sigmoid.social/109480732828653579)
> A large machine learning job spans many nodes and runs most efficiently when it has access to all of the hardware resources on each node. This allows GPUs to cross-communicate directly using NVLink, or GPUs to directly communicate with the NIC using GPUDirect. So for many of our workloads, a single pod occupies the entire node.
> We have very little HTTPS traffic, with no need for A/B testing, blue/green, or canaries. Pods communicate directly with one another on their pod IP addresses with MPI via SSH, not service endpoints. Service “discovery” is limited; we just do a one-time lookup for which pods are participating in MPI at job startup time.
+ [Terraform, Python, Chef, GPU workloads on 500+ node clusters](https://boards.greenhouse.io/openai/jobs/4315830004)
## Use-Cases
+ Code completion
+ Semantic search
## My Attempts
## Infra
+ Azure
+ [K8s](https://openai.com/blog/scaling-kubernetes-to-7500-nodes/) [Source here](https://jawns.club/@april@sigmoid.social/109480732828653579)
> A large machine learning job spans many nodes and runs most efficiently when it has access to all of the hardware resources on each node. This allows GPUs to cross-communicate directly using NVLink, or GPUs to directly communicate with the NIC using GPUDirect. So for many of our workloads, a single pod occupies the entire node.
> We have very little HTTPS traffic, with no need for A/B testing, blue/green, or canaries. Pods communicate directly with one another on their pod IP addresses with MPI via SSH, not service endpoints. Service “discovery” is limited; we just do a one-time lookup for which pods are participating in MPI at job startup time.
+ [Terraform, Python, Chef, GPU workloads on 500+ node clusters](https://boards.greenhouse.io/openai/jobs/4315830004)
## Use-Cases
+ Code completion
+ Semantic search
## My Attempts