ChatGPT appeared like an explosion on all my social media timelines. While I keep up with machine learning as an industry, I wasn't focused so much on this particular corner, and all the screenshots seemed like they came out of nowehre. What was this model? How did the chat prompting work? What was the context of OpenAI doing this work and collecting my prompts for training data?
I decided to do a quick investigation. Here's all the information I've found so far. I'm aggregating and synthesizing it as I go.
ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response. We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup. ChatGPT is fine-tuned from a model in the GPT-3.5 series
text-davinci-003 is an improvement on text-davinci-002

- OpenAI in 2019
- OpenAI models as a service - this will likely be offered as an API service by Azure AI
- The model data is recent as of 2021 and does offline inference (aka it doesn't know anything about, for example, the death of Queen Elizabeth 2).

Originally I asked about this on Twitter and didn't come up with much. My Twitter Thread Question on Training Data. But since then, independent researchers have been discussing and verifying the very opaque training data behind the OpenAI models.
A key component of GPT-3x models are Books1 and Books2, both of which are shrouded in mystery. Researchers have attempted to recrate the data using OpenBooks1 and 2.
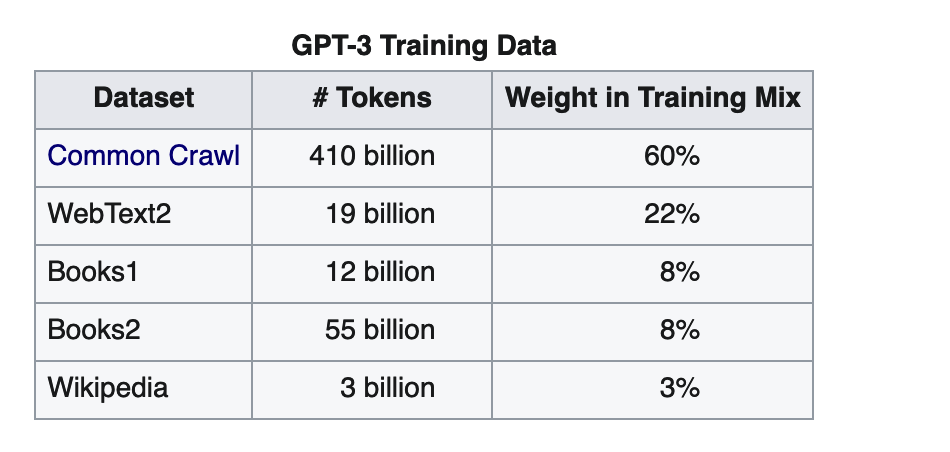
The model was trained on:
- Books1 - also known as BookCorpus. Here's a paper on BookCorpus, which maintains that it's free books scraped from smashwords.com.
- Books2 - No one knows exactly what this is, people suspect it's libgen
- Common Crawl
- WebText2 - an internet dataset created by scraping URLs extracted from Reddit submissions with a minimum score of 3 as a proxy for quality, deduplicated at the document level with MinHash
- What's in MyAI Paper, Source - Detailed dive into these datasets.

- My Twitter Thread Question on the Model
- Language Models are Few-Shot Learners: GPT3
- Model- reinforcement learning for language models
- Illutstrating Reinforcement Learning from Human Feedback Tutorial
- InstructGPT Blog Post
- InstructGPT Model Card
- Models Referred to as GPT 3.5
- OpenAI comes clean about GPT 3.5
- Possibly davinci-003
The policy model was evaluated by humans,
InstructGPT is then further fine-tuned on a dataset labeled by human labelers. The labelers comprise a team of about 40 contractors whom we hired through Upwork and ScaleAI. Our aim was to select a group of labelers who were sensitive to the preferences of different demographic groups, and who were good at identifying outputs that were potentially harmful. Thus, we conducted a screening test designed to measure labeler performance on these axes. We selected labelers who performed well on this test. We collaborated closely with the labelers over the course of the project. We had an onboarding process to train labelers on the project, wrote detailed instructions for each task, and answered labeler questions in a shared chat room.
- Azure
- K8s Source here
A large machine learning job spans many nodes and runs most efficiently when it has access to all of the hardware resources on each node. This allows GPUs to cross-communicate directly using NVLink, or GPUs to directly communicate with the NIC using GPUDirect. So for many of our workloads, a single pod occupies the entire node.
We have very little HTTPS traffic, with no need for A/B testing, blue/green, or canaries. Pods communicate directly with one another on their pod IP addresses with MPI via SSH, not service endpoints. Service “discovery” is limited; we just do a one-time lookup for which pods are participating in MPI at job startup time.
- Code completion
- Semantic search
- Creative writing, aka backstories for characters
- A lot of potential prompts







bring the top tier prompts to God Tier Prompts! come have fun ✨