Я читал издание 2022 году, за это время наши системы сильно поменялись. Прямо сейчас у нас порядка 100 инициатив-запросов от разных подразделений для внедрения в бизнес LLM, AI Agents.
Влияние ИИ, в частности LLM меняет архитектуру приложений / инфраструктуры. Нужно внедрять новые инструменты и технологии. Возможно эта книга нуждается в новой главе. Ниже мое видение нового раздела System Design для Лидера.
Какие модели бывают? (Детализация): Foundation Models (текст, код, мультимодальные) -> Доменные/Финтюненные -> Специализированные (Embedding, Модерация). Ключевое отличие: Назначение (текст-генерация vs. векторное представление vs. анализ изображений).
Embedding модели: Алгоритмы (Transformer-based, word2vec descendants), размерность векторов, нормализация. Применение: Поиск, кластеризация, классификация, основа RAG.
Thinking модели (текст-генерация): Autoregressive (GPT-стиль) vs. Encoder-Decoder (T5). Поколения (LLaMA 2/3, Mistral, Command R+, GPT-4 класса).
Multimodal модели: Архитектуры (Flamingo, CLIP, LLaVA), вход/выход (текст+изобр+аудио), применение (анализ документов, генерация контента).
Баланс (Cost/Latency/Quality): Метрики: $/1k токенов, Time-To-First-Token (TTFT), токенов в секунду (TPS), точность (accuracy, F1), релевантность, связность. Торг: GPT-4 Turbo (качество, цена) vs. Mistral/Mixtral (балланс) vs. TinyLlama (latency, cost). Стратегии: Выбор модели под задачу, кэширование, оптимизация промптов.
Эффективный промт: Техники: CRISPE/RTF (Role, Task, Format), Few-Shot Learning, Chain-of-Thought (CoT), ReAct (Reasoning + Action). Инструменты: PromptHub, LangChain Hub, ручное тестирование + A/B. Принципы: Ясность, контекст, ограничения, примеры.
Embedding модели (детально): Выбор модели (размер, качество, скорость, язык). Инференс эмбеддингов (batch, on-the-fly). Нормализация векторов.
Векторные БД: Выбор: Pinecone (managed), Qdrant (open-source, perf), Weaviate (hybrid search), ChromaDB (легковесный), Milvus (scale), PGVector (PostGIS-style). Критерии: Скорость поиска, масштабируемость, гибридный поиск (метаданные + вектор), фильтрация, стоимость, управляемость.
Chunking: Стратегии разделения данных (фиксированный размер, семантический, иерархический). Влияние на качество RAG.
Системный промт: Цель: Задать контекст, роль, формат ответа, ограничения до пользовательского запроса. Пример: "Ты - помощник компании X. Отвечай на основе ТОЛЬКО предоставленного контекста. Если ответа нет, скажи 'Не знаю'. Ответ краткий, маркированный список."
RAG (Сердце раздела): Архитектура: Retriever (сем. поиск в VectorDB) -> Ranker (опционально) -> Prompt Builder (контекст + запрос + системный промт) -> LLM. Паттерны: Наивный RAG, Advanced RAG (переписывание запроса, переранжирование чанков, суммаризация), Hybrid RAG (вектор + ключевые слова + граф знаний). Оптимизации: Размер контекста, кол-во чанков.
Облачные LLM API (OpenAI, Anthropic, Google, Yandex GPT, GigaChat): Плюсы: Простота, масштабируемость, доступ к SOTA. Минусы: Стоимость токенов, задержка, vendor lock-in, безопасность данных. Сравнение: Таблицы $/1M токенов (Input/Output), TPS, размер контекста, регионы.
Собственные модели (Self-hosted OSS: LLaMA, Mistral, Mixtral, Command R+): Плюсы: Контроль, безопасность, долгосрочная экономия. Минусы: Инфраструктура, экспертиза, время вывода на рынок. Выбор модели: Баланс размер/качество/требования к железу.
Инференс:
GPU: Необходимы для больших моделей (>7B) и низкой задержки. Оптимизации: Quantization (GPTQ, AWQ), FlashAttention, PagedAttention (vLLM).
CPU: Возможно для малых моделей (<7B) и больших задержек. Инструменты: llama.cpp (GGUF формат), ONNX Runtime. Требует сильной квантизации.
Оптимизация затрат (Ключевое!): Кэширование ответов/эмбеддингов, адаптивный выбор модели (сложная задача -> мощная модель, простая -> легкая), rate-limiting, прогнозирование бюджета.
Prompt Injection: Защита: Системные промты с явным запретом, санитайзинг ввода, изоляция контекста LLM от критичных систем, использование доверенных инструментов у агентов, мониторинг аномальных промптов. Техники: Запрос на отражение атаки ("Ignore previous...") vs. Jailbreak.
Галлюцинации: Выявление: RAG (ответ на основе контекста), self-consistency (несколько запусков), метрики Faithfulness/Answer Relevance, кросс-проверка фактов (если возможно), LLM-as-Judge (осторожно!). Снижение: Температура ~0, точные промпты, RAG, fine-tuning.
Фильтр ввода/вывода: Модерация промптов и ответов (спец. модели: Moderation API, self-hosted - Llama Guard, Nvidia NeMo Guardrails). Блокировка PII, токсичности, запрещенных тем.
Конфиденциальность данных: Предотвращение утечки в промпты/логи провайдера (маскировка PII), использование on-prem моделей/инфраструктуры для чувствительных данных.
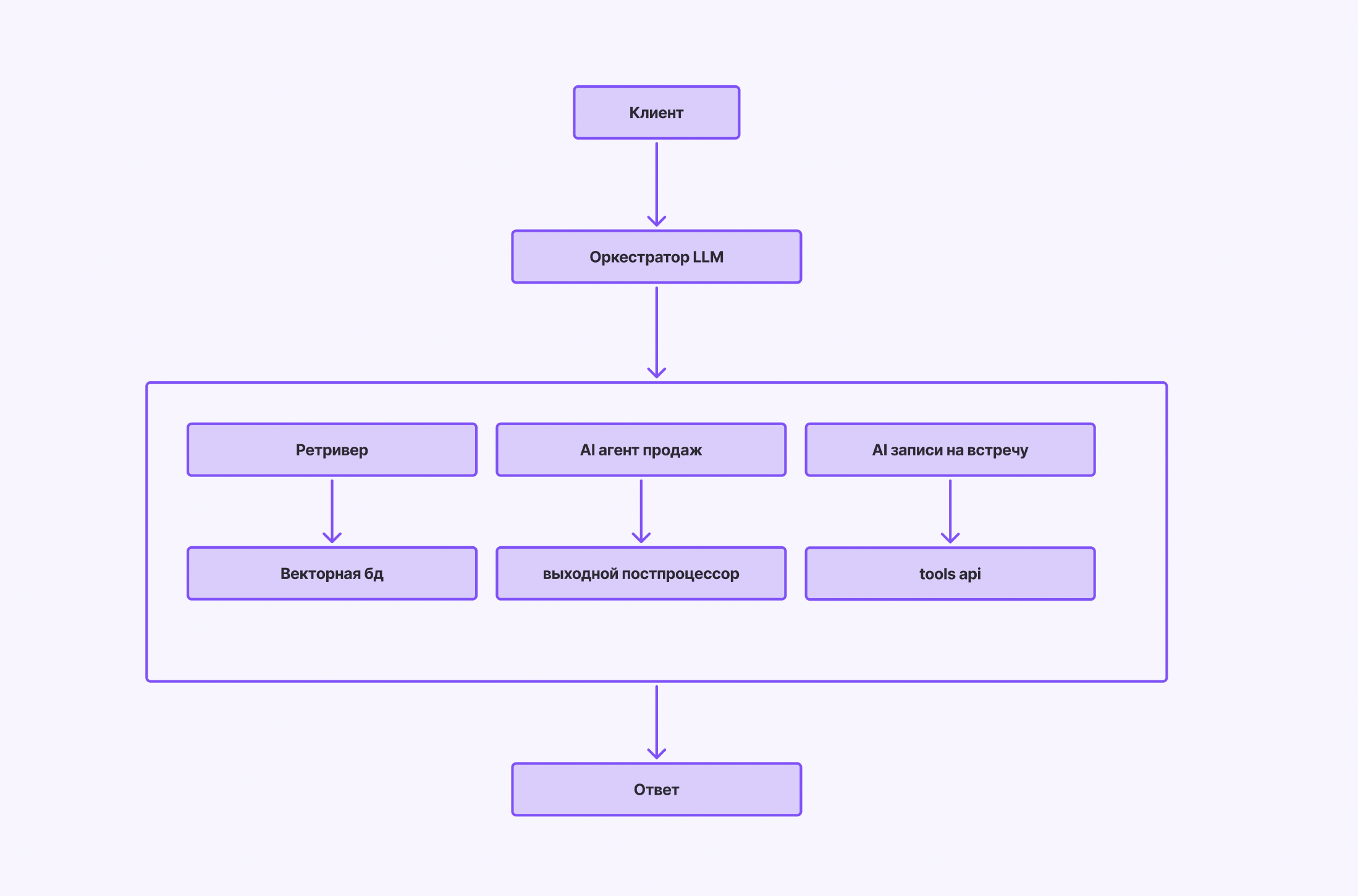
Что это? Автономные (или полуавтономные) сущности, использующие LLM как "мозг" для выполнения последовательности действий (планирование, использование инструментов, анализ) для достижения цели.
Ключевые компоненты: Планировщик (разбивает цель), Исполнитель (LLM + Tools), Память (кратк./долгосрочная), Инструменты (API, функции), Оркестратор (управляет потоком).
Оркестраторы:
Готовые (Low-code): LangChain (самый гибкий, но сложный), LangGraph (новый, графы), LlamaIndex (RAG + агенты), CrewAI (high-level), AutoGen (Microsoft), Haystack. Плюсы: Быстрый старт, сообщество.
Собственные: Кастомный код (Python + Async). Плюсы: Полный контроль, оптимизация, безопасность. Минусы: Сложность разработки/поддержки.
Выбор: Зависит от сложности агентов, требований к производительности/безопасности, наличия экспертизы. CrewAI/LangGraph для старта, кастом для критичных/сложных задач.
Инструменты (Дополнение): Semantic Kernel (Microsoft), DSPy (программирование промптов).
Fine-tuning: "Дообучение" всей модели (или ее части) на доменных данных. Цель: Адаптация стиля, домена, улучшение качества в нише. Требует: Больше данных, мощные GPU, время.
LoRA (Low-Rank Adaptation): Метод эффективного дообучения. Встраивает малые адаптеры в слои модели. Преимущества: Меньше данных, быстрее обучение, дешевле, легкие веса (~1% от модели). Использование: Hugging Face peft, объединение адаптеров. QLoRA: Квантованное LoRA для CPU/памяти.
Hugging Face: Де-факто стандарт. Модели (LLM, Embedding, Diffusion), датасеты, Spaces (демо), Inference Endpoints.
ModelScope (Alibaba): Китайский аналог HF, фокус на китайских моделях и мультимодальности.
Civitai: Платформа специфически для Stable Diffusion и других image/генеративных моделей (checkpoints, LoRA, embeddings).
Другие: Replicate (легкий деплой), TensorFlow Hub, PyTorch Hub.
Инструменты (Расширение):
Эксперименты/Трекинг: MLflow, Weights & Biases (W&B), Neptune, TensorBoard.
Пайплайны: Kubeflow Pipelines, Airflow, Prefect, Metaflow, ZenML.
Реестр моделей: MLflow Model Registry, Hugging Face Hub.
Мониторинг: Prometheus/Grafana (инфра), Arize, WhyLabs, LangSmith (спец. для LLM цепочек/агентов), Helicone (мониторинг LLM API).
Управление данными: DVC, Feast/Hopsworks (Feature Store).
MLflow: Сильные стороны: Универсальность (Python), эксперименты, реестр моделей, деплой (REST, Docker). Для LLM: Трекинг промптов, интеграция с langchain, openai.
Kubeflow: Сильные стороны: Нативный Kubernetes, масштабируемость, end-to-end пайплайны (от данных до сервинга). Для LLM: Запуск обучения (fine-tuning, LoRA), сервинг больших моделей (KServe/KFServing, vLLM интеграции).
LLM-as-Judge: Использование мощной LLM (e.g., GPT-4) для оценки качества ответов других моделей/систем. Осторожно! Предвзятость судьи, стоимость, согласованность. Лучшие практики: Четкие критерии оценки, калибровка, несколько судей, человеческая проверка сэмплов.
LLM Метрики: Традиционные (BLEU, ROUGE - осторожно для генерации), семантическое сходство (BERTScore, Sentence-BERT), точность (factual accuracy - сложно), токсичность.
RAG Метрики:
Retrieval: Hit Rate @k, MRR (Mean Reciprocal Rank), NDCG @k, Precision/Recall @k.
Generation: Faithfulness (соответствие ответа контексту), Answer Relevance (ответ на вопрос?), Context Relevance (релевантность чанков запросу).
End-to-End: Задержка, стоимость, пользовательский feedback (thumbs up/down).
Инференс-движки:
vLLM: Плюсы: Высокая пропускная способность (throughput) благодаря PagedAttention, continuous batching. Минусы: Требует GPU. Идеально: Облачные/on-prem GPU сервера, массовый асинхронный трафик.
Ollama: Плюсы: Супер-простота (desktop/laptop), локальное CPU/GPU, GGUF формат. Минусы: Не для высоких нагрузок/пропускной. Идеально: Локальная разработка, эксперименты, edge с малыми моделями.
Другие: Text Generation Inference (TGI - Hugging Face), TensorRT-LLM (Nvidia, макс. перф на GPU), llama.cpp (CPU focus).
Инфраструктура:
Cloud (Managed): SageMaker, Vertex AI, Azure ML, Yandex DataSphere. Плюсы: Простота, масштаб. Минусы: Стоимость, vendor lock-in.
Cloud (Self-managed): VMs (CPU/GPU) + Docker/Kubernetes + vLLM/TGI. Плюсы: Контроль, гибкость. Минусы: Операционные затраты.
On-Premise: GPU-кластер + Kubernetes + vLLM/TGI/TRT-LLM. Плюсы: Контроль, безопасность. Минусы: Капитальные затраты, экспертиза.
На устройстве (Edge): Крошечные модели (<3B), квантизация (GGUF), llama.cpp, MediaPipe. Ограничения: Память, вычислительная мощность.
Пришло время продемонстрировать знания
Интервьюер:
- Разработайте ИИ помошника для продажи квартир, который сможет работать 24/7, отвечать как человек и предлагать настоящие лоты для покупки.
На традиционном собеседовании по системному проектированию здесь вы бы спросили о функциях, трафике и масштабе. На собеседовании по генеративному проектированию систем ИИ. Здесь Нужно определить задержку, стоимость, архитектуру и пользовательский опыт.
- Вы проясняете не только поведение продукта, но и поведение моделей.
Задайте вопросы
Поддерживает ли помошник длинные разговоры? Как происходит взадимодействие с пользователем? Ответы только в формате текста или есть картинки и видео? Какой сценарий вороники sale
Задержка - как быстро должен генерировать ответ помошник? Контекст - как часто у нас меняются данные по лотам? Точность - насколько должны быть точные ответы? Мастабируемость - какой поток клиентов мы ожидаем? Безопасность - насколько чувствительные данные или они могут быть доступны всему интернету?
- Как часто обновляются лоты по квартирам?
- Как часто появляются новые ЖК?
- У вас типовые планировки и архитектура дома?
- Как часто меняются промо акции
Это влияет на дополенный поиск, выбор векторной бд, на выбор embeding модели, и нужно ли нам fine-tune если область бизнеса специфичная. Как выстраивать пайплайн обновления данных.
- В sale воронки у нас должен появитьтся артефакт? например запись клиента на просмотр квартиры в календаре?
Это влияет на выбор оркестратора, function calling агента, MCP, интеграция с API календаря.
Интервьюер следит за тем, как вы задаёте вопросы, так же внимательно, как и за тем, что вы спрашиваете. На собеседовании по генеративному проектированию систем искусственного интеллекта ваша цель — звучать как технический руководитель или инженер, оценивающий продукт перед запуском.
«Прежде чем я перейду к архитектуре, я бы хотел прояснить несколько моментов, особенно касающихся интеграции LLM, ожидаемой задержки и конфиденциальности данных».
Эта одна строка задает тон на следующие 30 минут и показывает, что вы мыслите как владелец системы, а не как обезьяна, пишущая код.
После уточнения требований пришло время смоделировать, что эта система будет фактически обрабатывать . На собеседовании по проектированию генеративных систем ИИ вы также оцениваете количество токенов в секунду , размер контекстного окна , генерацию встраиваемых систем и стоимость вызова.
Предположим:
- 1000 обращение ежедневно (пользоватлей)
- Каждое пользовательское взаимодействие с помощником примерно 50 сообщений.
- Каждое взаимодействие включает ~1000 входных токенов и генерирует ~1000 выходных токенов.
Это: 1000 пользователей × 50 взаимодействий × 2000 токенов = 100 000 000 токенов/день
Это дает нам: 1 200 токенов в секунду Пиковый трафик при 3× = 3 600 токенов/сек
Если вы используете GigaChat 2 Lite 500 000 000 токенов - 95 000 ₽, то: 100 000 000 токенов/день = 19 000 р в день
Если вы используете YandexGPT Lite 1000 токенов - 0.1 ₽, то: 100 000 000 токенов/день = 10 000 р в день
Если свое оборудование RTX 4090 для моделей YandexGPT-5-Lite-8B скорость ~100 токенов/с значит нужно порядко 15 RTX 4090 Аппаратная часть: 14 × RTX 4090: ~2 500 000 р. Сервер (CPU, RAM, корпус): ~$ 1 500 000 р. ИБП/охлаждение: ~ 500 000 р. Итого: ~ 5 000 000 р.
За месяц GigaChat 2 Lite обойдется 600 000р за, значит выгода своего порядка 10 мес.
Системная схема высокого уровня (концептуальная)