A Regex is known as a Regular expressions, or regex for short, are a series of special characters that define a search pattern. We will navigate a search pattern bases on literal characters that will produce a regex search pattern with a result by deliminating meta characters withing each of the data sets to redact the required results to each of the respected regex components. In this document I will go about describing each of the respected regular expressions in detail and provide a functional example for each regular expression to better help the reader understand how the regular expressions are written and what they are doing.
This document will introduce methods & solutions to provide the reader with the respected solutions that will supplement their understanding of regular expressions. Below in the table of contents I will address each of the topics in detail, provide supporting resources, and best explain and demonstrate these regular expressions with a functioning example. I will include a code snippet of each of the respected regex functions for the reader. In these running examples I will outline the meta characters and explain them such as; \d for number and . for any character as well as * for 0 or more characters and also combine .* for any character 0 or more of which is known as a 'wild card'.
- Anchors
- Quantifiers
- Grouping Constructs
- Bracket Expressions
- Character Classes
- The OR Operator
- Flags
- Character Escapes
- https://www.regular-expressions.info/anchors.html : The caret ^ matches the position before the first character in the string and $ matches right after the last character in the string. Anchors do not match characters, rather they match positions of characters before, inbetween, or after in a regular expression in a specific position of a string or value. These searches on anchors can only find zero-length matches but they can also be used to create searches for complications. A user can trim the leading white space with the regex anchor function of: ^\s+ and you can match the trailing whitespace with the regex function of \s+$. When dealing with a string that runs multiple lines the regex command of \n indicates a line break. Strings ending with multi line breaks can use regex functions in multi-line mode can leverage the \Z to match before any number of trailing line breaks as well as the end of a string.

- http://docs.microsoft.com/en-us/dotnet/standard/base-types/quantifiers-in-regular-expressions : According to the Microsoft docs on quantifiers they are a specification of how many instances of a character, group, or character class that must be present in the input for a match to not be found. Examples of this can be expressed in Greedy Quantifiers and Lazy Quantifiers. A few examples of a greedy quantifier inclue * (matched zero or more times), + (matches one or more times), ? (matches zero or one time), { n } (matches exactly n amount of times), { n ,} (matches atleast n times), and { n , m } (matches from n to m times). Lazy Quantifiers are referenced simalarly in the examples above the only difference is each of these examples above have a trailing ? mark at the end of the quantifier that make them a Lazy Quantifier.
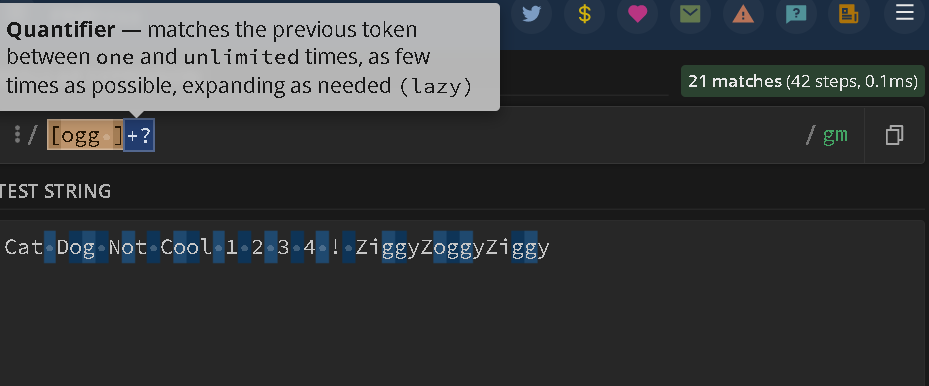
- https://docs.microsoft.com/en-us/dotnet/standard/base-types/grouping-constructs-in-regular-expressions : A Grouping Construct portrays a subexpression of a regex and captures the substring of the input string. You can use these Grouping Constructs to:
1 Match a subexpression that is repeated in the input string.
2 Apply to a regex in a quantifier to a given subexpression that has multiple language elements.
3 Include grouping constructs in a subexpression in the string that is returned by the regex to us a regex.replace & match.result form of methods.
4 Retreive specific or individual subexpressions from the match.groups property and then process each one seperately from the entirety of a matches text. These Grouping Constructs come in two types: Capturing & Noncapturing.
Grouping construct Capturing or noncapturing
- Matched subexpressions Capturing
- Named matched subexpressions Capturing
- Balancing group definitions Capturing
- Noncapturing groups Noncapturing
- Group options Noncapturing
- Zero-width positive lookahead assertions Noncapturing
- Zero-width negative lookahead assertions Noncapturing
- Zero-width positive lookbehind assertions Noncapturing
- Zero-width negative lookbehind assertions Noncapturing
- Atomic groups Noncapturing
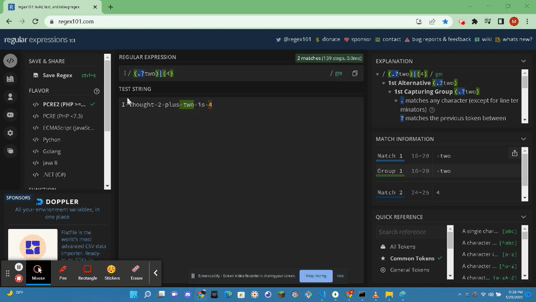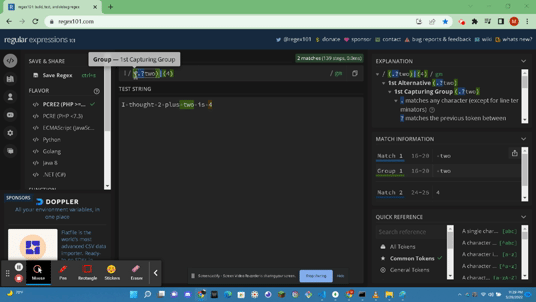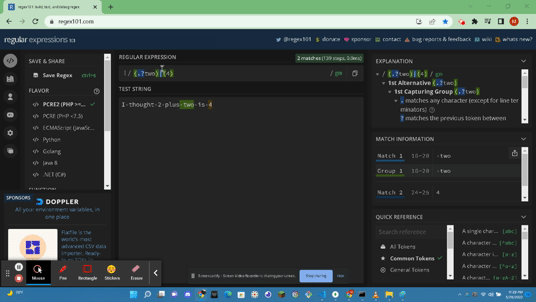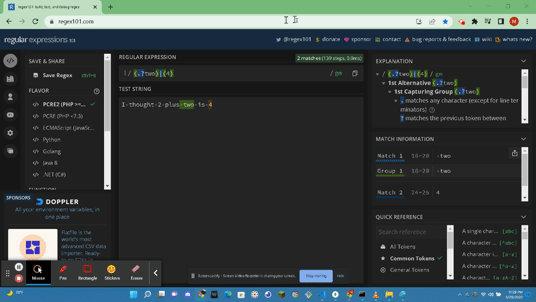
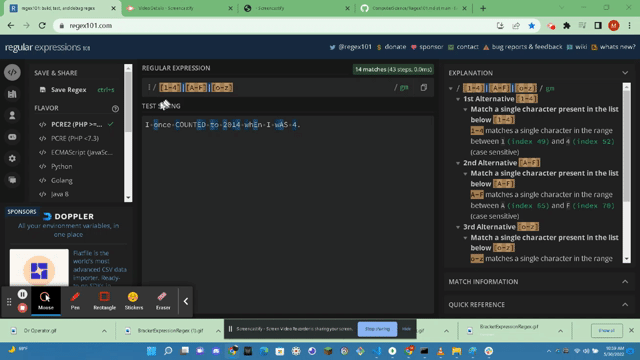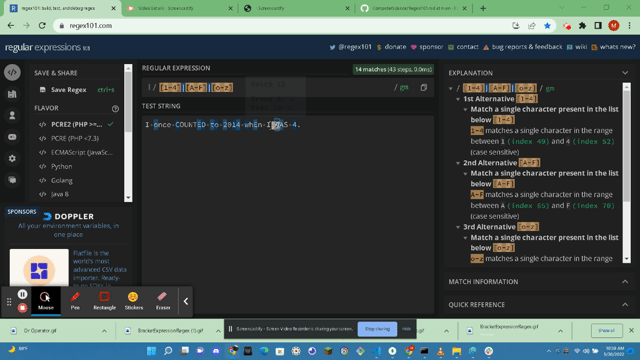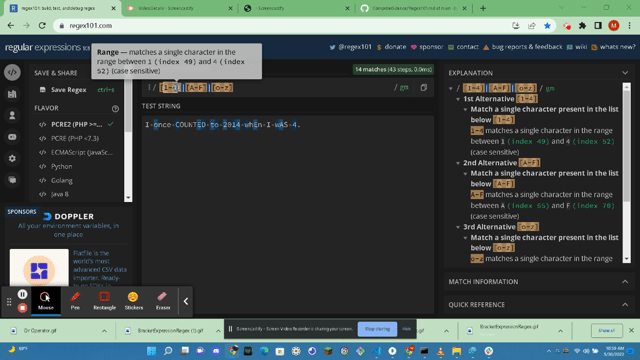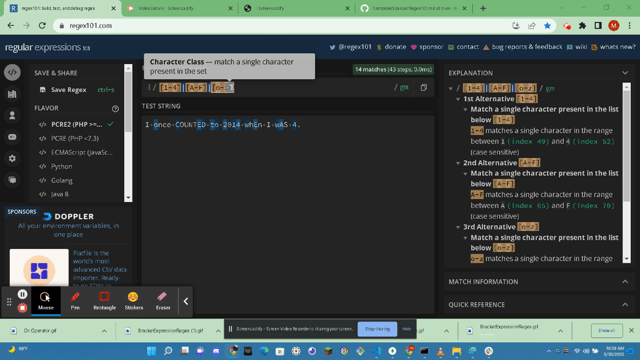
- https://www.ibm.com/docs/en/netcoolomnibus/8.1?topic=SSSHTQ_8.1.0/com.ibm.netcool_OMNIbus.doc_8.1.0/omnibus/wip/common/reference/omn_ref_re_bracketexpressions.html : According to IBM a Bracket Expression is used to match a single character or a collating element.The hyphen character (-) inbetween charecters within a bracket will match ranges within the scope of those characters. Using the { } brackets we can use the brackets with a combination of a number to declare a number of digits in a string to match. Using the carot symbol ^ we can match any characters except those withing the square brackets, only if the carot is the first character after the opening [ or else it will be treated as a generic charecter and same applys to the hyphen (-). Other Metacharacters withing square brackets will be treated as normal characters and do not require an escape character.
For Example:
- [b-g] : In this expression we will match characters b,c,d,e,f,g.
- [xy7-9] : In this expression we will match x,y,7,8,9.
- [yY] [eE] [sS] : In this expression we will match any spelling of yes, YES, Yes, YEs, yES and so on of any combination.
- [^4-7] : Matches any characters and numbers except 4,5,6,7.
- [.fu.] : Matches a multi-character collating element, such as fun.
- [=t=] : Matches all collating elements with the same primary sort order as the element, including this element contained as itself.
- https://www.regular-expressions.info/charclass.html : Character Classes are also called a Character Set. Character sets are regex's that will match only one out of several characters. There are also Negated Character Classes and these classes match any character that is not in the character class. Such as invisible line breaks. You can also leverage metacharacters inside character class regex statements.

- https://www.ocpsoft.org/tutorials/regular-expressions/or-in-regex/ : The OR Operation will allow us to prefor a second match using the Pipe Character ( | ). You can use grouping and alternations in the OR operation by incorporating a ( ?: ) in the statement. Here is a lightweight example of the OR operation. Also the ( \w ) statement is known as the look-ahead and look-behind statement incorporating ( ?= ) and ( ?! ) '^I eat (?= excellence | failure)\w+ for breakfast but I prefer eating ( ?! excellence | dog food)\w+$.'
- https://javascript.info/regexp-introduction#flags: According the javascript.info resource there are only 6 flags
- i : this flag will search for Case-Insensitive searches; meaning there is not a difference between fun and FUN in a search.
- g : This flag will search for ALL MATCHES. If we didnt use g then only the first match would get returned in our search.
- m : This flag will cover multiple lines as it is called Multiline Mode.
- s : This flag __enables 'DOTALL' mode that allows the . to match ( \n ); or a new line character.
- u : This flag enables Unicode Support. This enables processing of surrogate pairs.
- y : This flag enables Sticky Mode and searches at the exact position covered in the sticky search position.
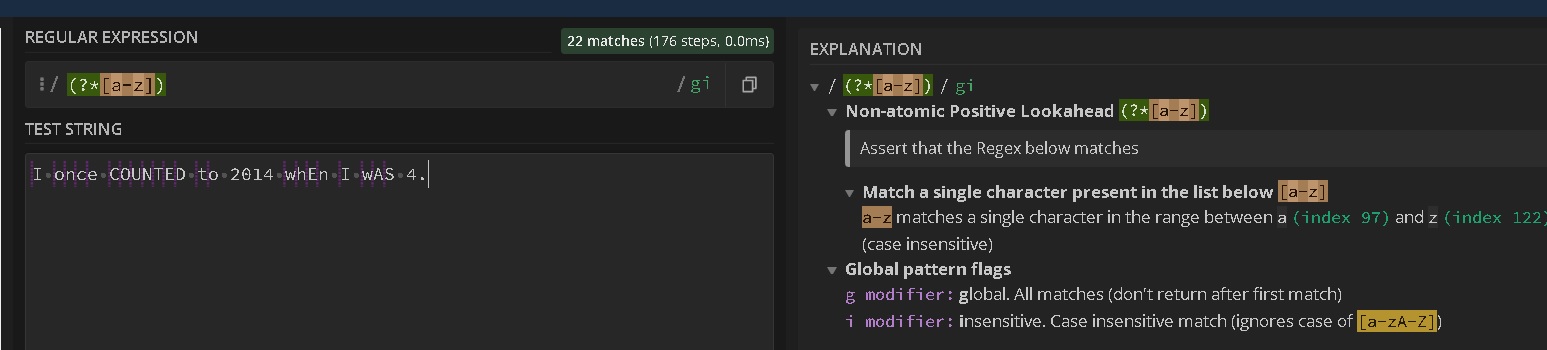
- https://www.jmp.com/support/help/zh/15.2/index.shtml#page/jmp/escaped-characters-in-regular-expressions.shtml : The backslash produces a literal character You can use the backslash with common character classes such as \s and \w for space and word characters. Also other escpaed characters are as follows:
- TwoBackslashes : single backslash
- \A :start of a __st__ring
- \b :word bounda__ry. The zero-length string between \w and \W or \W and \w.
- \B :not at a word boundary
- \cX :ASCII control character
- \d :single digit [0-9]
- \D :single character that is NOT a digit [^0-9]
- \E :stop processing escaped characters
- \l :match a single lowercase letter [a-z]
- \L :single character that is not lowercase [^a-z]
- \Q :ignore escaped characters until \E is found
- \r :carriage return
- \s :single whitespace character
- \S :single character that is NOT white space
- \u :single uppercase character [A-Z]
- \U :single character that is not uppercase [^A-Z]
- \w :word character [a-zA-Z0-9_]
- \W :single character that is NOT a word character [^a-zA-Z0-9_]
- \x00-\xFF :hexadecimal character
- \x{0000}-\x{FFFF} :Unicode code point
- \Z :end of a string before the line break

I am BinaryBitBytes, a junior full stack developer learning the craft of coding like a a keyboard warrior. Here Is the link to the summary of Regex101 on my GitHub profile: https://github.com/BinaryBitBytes/ComputerScience