This gist works as a hands-on note for running llama.cpp on various GPU. It may out-of-date due to the proj update.
This is only a personal record so readers may not have an out-of-box hands-on experience
Record the verified configs. The project is still developing very fast, so the granularity for the record is specified to the commit id.
| Imple. | Device | OS | llama.cpp version | 3rd party version | Step |
|---|---|---|---|---|---|
| Cuda | 3060Ti (together with i5-12600KF) | Ubuntu 22.04 | llama.cpp | CUDA 12.1 | CUDA-ubuntu-2204 |
| OpenCL | UHD 630 (on a i7-9750H) | Windows 10 | llama.cpp | OpenCL-SDK CLBlast |
OpenCL-windows-10 |
Step 1: Install CUDA 12.1. I am pretty sure some other version around 12.1 could work but I put the installation spec link here.
 The only extra thing we may need to do is to add the bin (including nvcc) to PATH.
The only extra thing we may need to do is to add the bin (including nvcc) to PATH.
Step 2: Clone the llama.cpp (be sure to checkout the commit id I used in previous table)
Step 3: make LLAMA_CUBLAS=1. The whole process is quite smooth (I guess CUDA community is widely adopted so that a smooth installation and out-of-box performance could be achieved.
Step 4: prepare a ckpt (just download one from huggingface, here is what I use)
Step 5: ./main -m ~/Downloads/llama-7b.ggmlv3.q4_0.bin -p "Once upon a time" -n 128 -t 6 -ngl 35. Here a critical parameter is -ngl which states how many layers are "offloaded" to GPU. So that some GPU w/o enough VMem could also work.
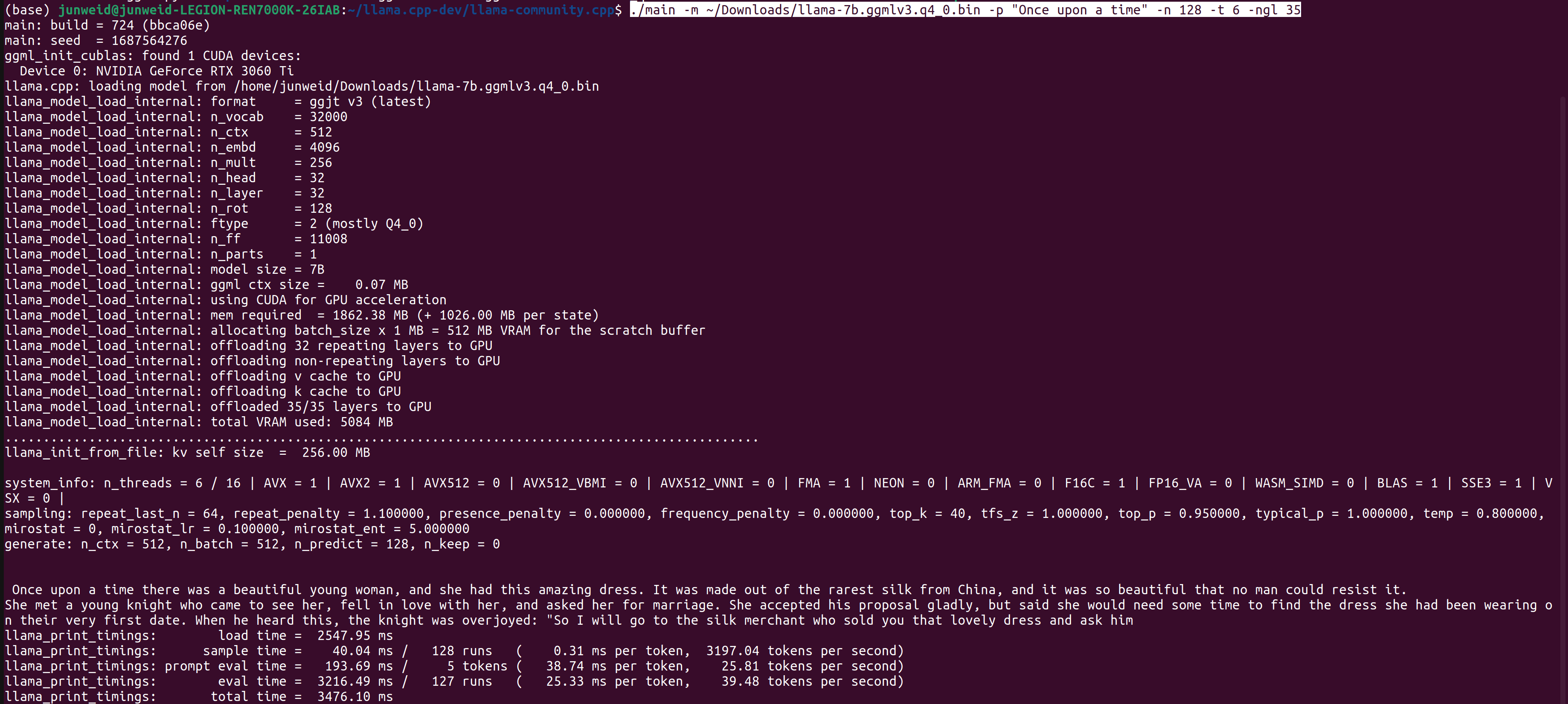
This is really not a mature way to run GGML, it may suitable for developers rather than users
Step 1: Basic windows C/C++ developing environment. This includes cmake (3.27.0-rc3 is the version I use) and Visual Studio 2022. The module need to be installed is
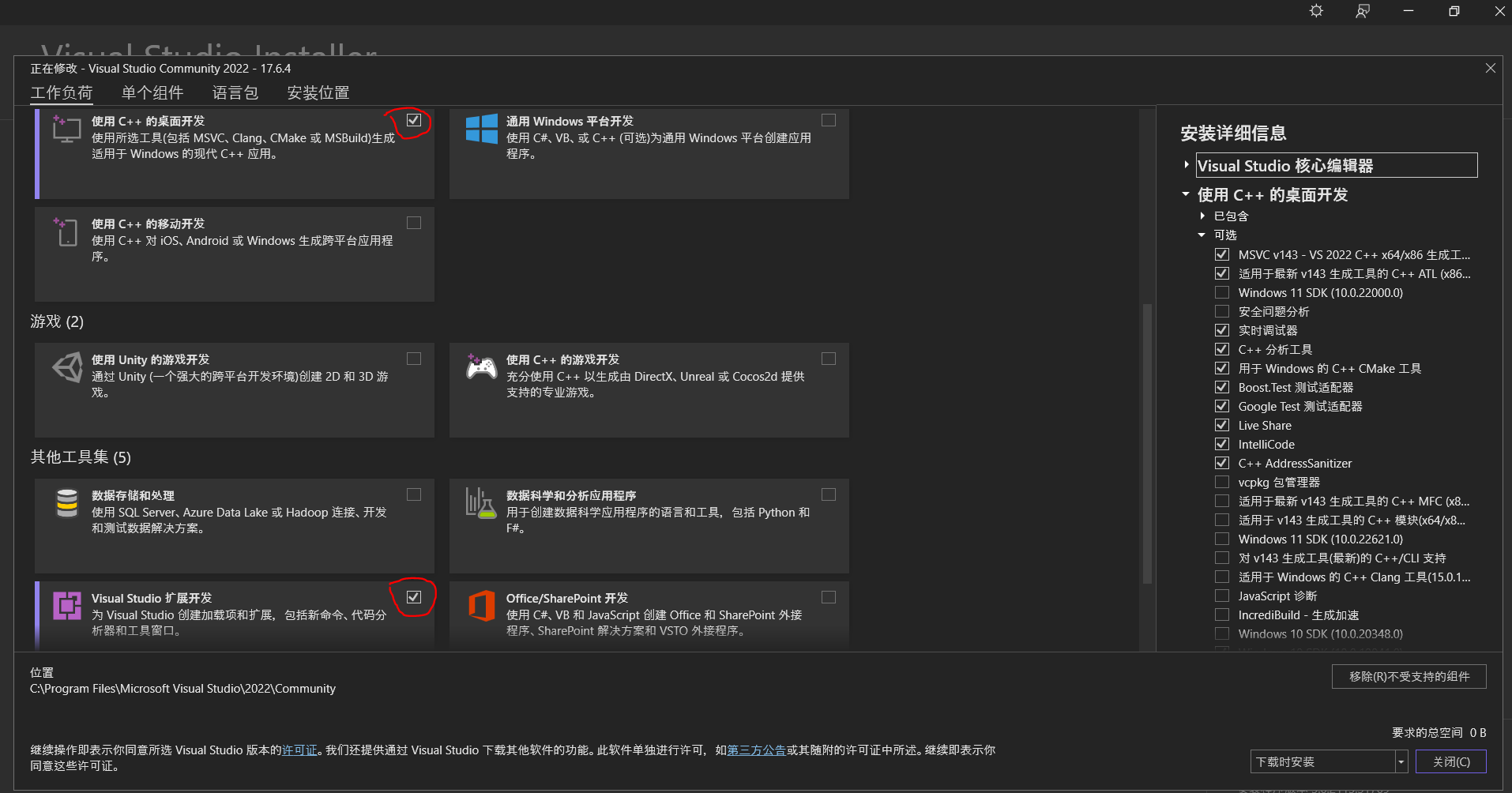
Step 2: Add some extra works include add some path items. (This may not really required)
C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Tools\MSVC\14.30.30705\bin\Hostx64\x64C:\Program Files\CMake\bin
Step 3: Intel vcpkg: https://vcpkg.io/en/getting-started.html, and add it to path
C:\llama.cpp-dev\vcpkg
Step 4: OpenCL-SDK: Build from source and install https://github.com/KhronosGroup/OpenCL-SDK/tree/ae7fcae82fe0b7bcc272e43fc324181b2d544eea#example-build
Step 5: CLBlast: Build from source and install https://github.com/CNugteren/CLBlast/tree/28a61c53a69ad598cd3ed8992fb6be88643f3c4b
git clone https://github.com/CNugteren/CLBlast.git
mkdir CLBlast/build
cd CLBlast/build
cmake .. -DBUILD_SHARED_LIBS=OFF -DTUNERS=OFF
cmake --build . --config Release
cmake --install .Step 6: Build llama.cpp https://github.com/ggerganov/llama.cpp/tree/bbca06e26949686d61a5126332680ba3cccf235c
# CMakeLists.txt
# add this to line 4
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} /MT")and run
mkdir build
cd build
cmake .. -DLLAMA_CLBLAST=ON
cmake --build . --config ReleaseStep 7: prepare a ckpt (just download one from huggingface, here is what I use)
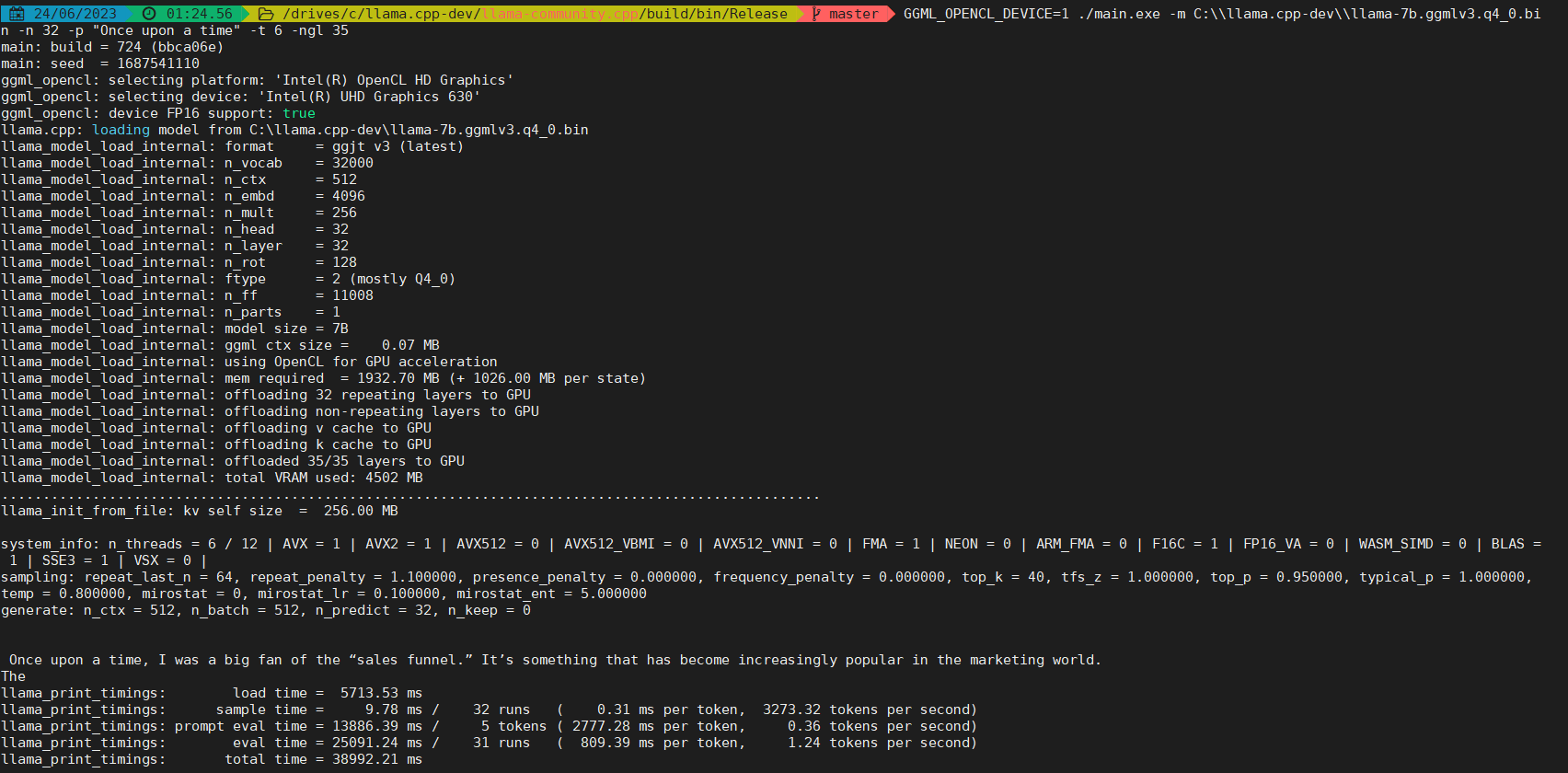
Step 8: GGML_OPENCL_DEVICE=1 ./main.exe -m C:\\llama.cpp-dev\\llama-7b.ggmlv3.q4_0.bin -n 128 -p "Once upon a time" -t 6 -ngl 35 Here a critical parameter is -ngl which states how many layers are "offloaded" to GPU. So that some GPU w/o enough VMem could also work. On my laptop, 2 devices support OpenCL and the intel igpu is the second one, so we need to set GGML_OPENCL_DEVICE=1
800ms/token :(, maybe CLBlast is not optimized for intel igpu, OneMKL is a promising choice. openvinotoolkit/openvino#10464 (comment) could be another reason.
Based on my experience when run ggml on A730M, add more details:
http_proxyandhttps_proxyto clone github repo, then must unset these variables when use.\vcpkg\bootstrap-vcpkg.batto build vcpkg (In Step3).GGML_OPENCL_DEVICE=1(In Step8), it's better to use linux bash shell (such as use mobaxterm).