-
MongoDB là cơ sở dữ liệu đa nền tảng, hướng documents (document oriented).
-
Mongo có 2 khái niệm là collection và document.
-
Một server Mongo thì có thể chứa nhiều database.
-
Database gồm nhiều collection, mỗi collection gồm nhiều document.
-
Document là một tập cái cặp key - value, document trong một collection có schema động, chúng không nhất thiết phải có cùng tập các field hay cùng cấu trúc.
-
Bảng tương quan giữa RDBMS(Relational Database Management System) và MongoDB:

- _id là một số hexa 12bytes để đảm bảo mỗi document là unique, nếu ko truyền vào _id lúc tạo thì mongo sẽ tự tạo cho bạn. Với 4 bytes đầu sẽ là timestamp hiện tại, 3 bytes tiếp theo là machine id, 2 bytes tiếp theo là cho process id của MongoDB Server và 3 bytes cuối là giá trị tăng dần.
_id: ObjectId(4 bytes timestamp, 3 bytes machine id, 2 bytes process id, 3 bytes incrementer)
- Môi trường:
- db.help() -> sẽ lấy ra danh sách các câu lệnh mongo client cung cấp
- db.stats() -> sẽ lấy ra tên db, số lượng collection và document, ...
- MongoDB cung cấp 2 loại data model:
- Embedded data model
- Normalized data model
- Embedded data model
- Với model này, bạn có thể nhúng tất cả các dữ liệu liên quan trong một document, nó còn đc gọi với tên là de-normalized data model.
- Ví dụ
{
_id: ,
Emp_ID: "10025AE336"
Personal_details:{
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
},
Contact: {
e-mail: "[email protected]",
phone: "9848022338"
},
Address: {
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
}- Normalized Data Model
-
Với model này thì bạn có thể tham chiếu tới những sub document trong một document gốc.
-
Ví dụ:
- Employee
{ _id: <ObjectId101>, Emp_ID: "10025AE336" }
- Personal_details
{ _id: <ObjectId102>, empDocID: " ObjectId101", First_Name: "Radhika", Last_Name: "Sharma", Date_Of_Birth: "1995-09-26" }
- Address
{ _id: <ObjectId104>, empDocID: " ObjectId101", city: "Hyderabad", Area: "Madapur", State: "Telangana" }
-
Những lưu ý khi design Schema trong MongoDB:
- Design dựa trên user requirements.
- Kết hợp các object vào trong một document nếu bạn dùng chúng cùng nhau. Ngược lại thì tách chúng ra (nhưng đảm bảo là ko cần join).
- Duplicated dữ liệu (có giới hạn) vì dung lượng disk rẻ hơn so với thời gian tính toán (compute time).
- Tiến hành join khi write chứ k phải khi read.
- Tối ưu schema của bạn cho các trường hợp hay dùng.
- Thực hiện các tổ hợp phức tạp (complex aggregation) trong schema.
-
Các kiểu dữ liệu trong Mongo
String: phải tuân thủ đúng chuẩn utf8.Integer: có thể là 32bit hoặc 64bit tùy thuộc vào server của bạn.Boolean: true/falseDouble: biểu diễn số thựcMin/Max keys: kiểu này dùng để so sánh một giá trị với các BSON element thấp nhất và cao nhấtArrays: dùng để lưu một mảng hoặc nhiều giá trị vào một keyTimestamp: thuận tiện để ghi lại thời gian khi một document được tạo mới hoặc chỉnh sửaObject: được dùng cho việc nhúng các document vào document hiện tại (embedded document)Null: dùng để lưu trữ giá trị nullSymbol: được dùng như String, tuy nhiên nó thường dành riêng cho các ngôn ngữ sử dụng các loại kí tự cụ thể.Date: được dùng để lưu trữ thời gian, mặc định là thời gian hiện tại.ObjectID: dùng để lưu ID của documentBinary data: để để lưu dữ liệu binaryCode: dùng để lưu Javascript code vào documentRegular expression: dùng để lưu regular expression.
use DATABASE_NAME-> để tạo db mới nếu chưa có, hoặc dùng db đã có sẵn.db-> để xem db đang chọn hiện tạishow dbs-> lấy ra danh sách db đang có, để db đc lấy ra thì nó ít nhất phải có một document.db.dropDatabase()-> để xóa một db, nếu bạn k chọn một db nào thì db mặc định 'test' sẽ bị xóa.db.createCollection(name, options)-> tạo một collection với tên name và options (ko bắt buộc) là một document được dùng để cấu hình collection. Với mongo thì khi bạn tạo một document thì collection sẽ được tạo tự động.

db.COLLECTION_NAME.drop()-> xóa một collectionshow collections-> lấy ra tất cả collection của db
- Có thể dùng 2 method là insert() và save().
db.COLLECTION_NAME.insert(document)-> thêm document vào collection. Có thể truyền một mảng các document vào để insert.db.COLLECTION_NAME.insertOne(document)-> thêm một document vào collection.db.COLLECTION_NAME.insertMany(documents)-> thêm nhiều document vào collection
-
db.COLLECTION_NAME.find(condition)-> tìm và lấy ra tất cả document thỏa mãn điều kiện của collection -
pretty()-> format dữ liệu lấy ra với hàmdb.COLLECTION_NAME.find().pretty() -
db.COLLECTION_NAME.findOne(condition)-> tìm và lấy ra một document thỏa mãn điều kiện trong collection -
Các toán tử điều kiện
- So sánh bằng và không bằng:
{ <key>: { $eg: <value> } } { <key>: { $ne: <value> } }
-
Ví dụ:
db.mycol.find({'by': 'name'}).pretty()tương ứng vớiwhere by = "name"trong RDBMS -
Ví dụ:
db.mycol.find({'by': {$ne: 'name'}}).pretty()tương ứng vớiwhere by != "name"trong RDBMS -
So sánh nhỏ hơn và nhơ hơn bằng:
{ <key>: { $lt: <value> } } { <key>: { $lte: <value> } }
-
Ví dụ:
db.mycol.find({"views": {$lt: 10}})tương ứng vớiwhere views < 50trong RDBMS. -
So sánh lớn hơn và lớn hơn bằng
{ <key>: { $gt: <value> } } { <key>: { $gte: <value> } }
-
Ví dụ:
db.mycol.find({"views": {$gt: 10}})tương ứng vớiwhere views > 50trong RDBMS. -
Kiểm tra giá trị có và không có trong một mảng:
{ <key>: { $in: [array] } <key>: { $nin: [array] } }
-
Ví dụ:
db.mycol.find({'name': {$in: ['duy', 'hang']}})tương ứng vớiwhere name matches any of the value in: ['duy', 'hang']trong RDBMS. -
Ví dụ:
db.mycol.find({'name': {$nin: ['duy', 'hang']}})tương ứng vớiwhere name values is not in the array: ['duy', 'hang']trong RDBMS. -
Toán tử AND trong mongo:
db.mycol.find({$and: [ { <key1>: <value1> }, { <key2>: <value2> } ]}). -
Toán tử OR trong mongo:
db.mycol.find({$or: [ { <key1>: <value1> }, { <key2>: <value2> } ]}). -
Toán tử NOT trong mongo:
db.mycol.find({$not: { <key1>: <value1> }}). -
Toán tử NOR trong mongo:
db.mycol.find({$nor: [ { <key1>: <value1> }, { <key2>: <value2> } ]}). (không cái này và không cái kia).
-
Có thể dùng 2 method là update() và save(). Với
updatethì sẽ cập nhật giá trị trong document đã tồn tại cònsavethì sẽ thay thế document đang có bằng một document được truyền vào methodsave(). -
Cú pháp update:
db.COLLECTION_NAME.update(<điều kiện để tìm document>, <giá trị cần update> , <options - không bắt buộc>). -
Mặc định thì update sẽ chỉ update document đầu tiên thỏa mãn điều kiện, nếu muốn update tất cả thì cần thêm options
"multi": true -
Cú pháp save:
db.COLLECTION_NAME.save({_id: ObjectID(), NEW_DATA}). -
Cú pháp findOneAndUpdate:
db.COLLECTION_NAME.findOneAndUpdate(<điều kiện>, <dữ liệu update>)-> tìm document thỏa đk và update sau đó lấy ra document đã update. -
Cú pháp updateOne:
db.COLLECTION_NAME.updateOne(<điều kiện>, <dữ liệu update>)-> update một document thỏa đk. -
Cú pháp updateMany:
db.COLLECTION_NAME.updateMany(<điều kiện>, <dữ liệu update>)-> update tất cả document thỏa đk.
-
Method
removeđể xóa một document ra khỏi collection,remove()nhận vào 2 tham số là tiêu chí để xóa, và một cờ justOne, nếu set cờ này bằng true thì chỉ xóa 1 document thỏa tiêu chí. -
Cú pháp:
db.COLLECTION_NAME.remove(<tiêu chí xóa>, <justOne flag>)
- Dùng để lấy ra những field cần thiết chứ không lấy tất cả dữ liệu của một document.
- Với method
find()thì truyền vào tham số thứ 2 là một tập các field cần lấy (1) hoặc không lấy (0) dạng key-value. - Cú pháp:
db.COLLECTION_NAME.find({}, {<tên field>: <1 | 0>}) - Mặc định thì field _id luôn được lấy ra, nếu không muốn thì set
_id: 0.
-
Dùng để giới hạn số lượng document được lấy ra
-
Cú pháp:
db.COLLECTION_NAME.find().limit(NUMBER) -
Method
skip()dùng để bỏ qua một số lượng documents -
Cú pháp:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
-
Dùng để sắp xếp những document được lấy ra
-
Method
sort()nhận tham số là một list các field kèm với thứ tự sắp xếp,1là tăng dần,-1là giảm dần. -
Cú pháp:
db.COLLECTION_NAME.find().sort({KEY: 1})
-
Index hỗ trợ cho việc truy vấn(query) hiệu quả hơn. Nếu không có index thì MongoDB phải scan qua hết các document trong collection để lấy ra các document match với lệnh query đó. Việc scan này rất kém hiệu quả và yêu cầu MongoDB phải xử lí một lượng lớn dữ liệu.
-
Index là những cấu trúc dữ liệu đặc biệt, dùng để lưu trữ một phần nhỏ của tập dữ liệu để dễ dàng đi qua (duyệt qua - easy-to-traverse form). Index lưu trữ giá trị của một field cụ thể hoặc một tập các field, được sắp xếp theo giá trị của field như đã được chỉ định trong index.
-
Cú pháp:
db.COLLECTION_NAME.createIndex({KEY: <1 | -1>})- Với key là tên field
1là thứ tự tăng dần-1là thứ tự giảm dần
-
Một vài options tùy chọn khác là tham số thứ 2 của method
createIndex():background: -> Tạo index trong background để việc này không block những hoạt động khác của DB. Mặc định là false.unique: -> Tạo một unique index để collection không chấp nhận việc thêm vào document có index key hoặc key match với một giá trị tồn tại trong index. Mặc định là false.name: -> Tên của index. Nếu không chỉ định thì MongoDB sẽ tự tạo một index nam bằng cách nối các tên của index field và thứ tự sắp xếp.sparse: -> Nếu set bằng true thì index chỉ tham chiếu những document với field đc chỉ định. Những index sẽ dùng ít dung lượng hơn nhưng sẽ hành xử (behave) khác nhau trong một số trường hợp(đặc biệt là sắp xếp). Mặc định là false.expireAfterSeconds: -> đơn vị làgiây, được chỉ định như là một TTL(time to live) để kiểm soát thời gian MongoDB giữ lại những document trong collection này.weights: -> Weight là một số từ 1 đến 99,999 và biểu thị cho tầm quan trọng của field so với những field index khác theo khái niệm về điểm số.default_language: -> Đối với một text index thì ngôn ngữ sẽ xác định một tập các stop words và rules cho stemmer và tokenizer. Mặc định là English.language_override: -> Đối với một text index, chỉ định tên của một field được chứa trong document đó, thì language này dùng để override ngôn ngữ mặc định.
-
method
dropIndex()vàdropIndexes-> dùng để xóa index -
Cú pháp
db.COLLECTION_NAME.dropIndex({KEY: 1}) -
Cú pháp
db.COLLECTION_NAME.dropIndexes({KEY1: 1, KEY2: -1}) -
method
getIndexes()-> dùng để lấy ra danh sách indexes -
Cú pháp
db.COLLECTION_NAME.getIndexes()
-
Tập hợp các phép toán xử lí dữ liệu và trả về kết quả tính toán. Aggregation operators nhóm các dữ liệu từ nhiều documents lại với nhau, và thực hiện nhiều phép toán trên nhóm dữ liệu đó để trả về một giá trị. Trong SQL thì count(*) và những câu lệnh với group by tương tự như MongoDB aggregation.
-
Cú pháp:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)- Ví dụ:
{ _id: ObjectId(7df78ad8902c) title: 'MongoDB Overview', description: 'MongoDB is no sql database', by_user: 'tutorials point', url: 'http://www.tutorialspoint.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 }, { _id: ObjectId(7df78ad8902d) title: 'NoSQL Overview', description: 'No sql database is very fast', by_user: 'tutorials point', url: 'http://www.tutorialspoint.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 10 }, { _id: ObjectId(7df78ad8902e) title: 'Neo4j Overview', description: 'Neo4j is no sql database', by_user: 'Neo4j', url: 'http://www.neo4j.com', tags: ['neo4j', 'database', 'NoSQL'], likes: 750 },
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
- Kết quả:
{ "_id" : "tutorials point", "num_tutorial" : 2 } { "_id" : "Neo4j", "num_tutorial" : 1 }
-
Câu lệnh trên ứng vs câu SQL select by_user, count(*) from mycol group by by_user.
-
Các expressions của aggregation:
-
$sum: Tổng giá trị đã xác định từ tất cả các documents trong collection.- Ví dụ:
db.mycol.aggregate([{ $group: { _id: "$by_user", num_tutorial: { $sum: "$likes" } } }])
- Ví dụ:
-
$avg: Tính trung bình cộng của tất cả các giá trị nhận được từ tất cả document trong collection.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", num_tutorial: { $avg: "$likes" } } } ])
- Ví dụ:
-
$min: Lấy giá trị nhỏ nhất trong các giá trị tương ứng từ tất cả document trong collection.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", num_tutorial: { $min: "$likes" } } } ])
- Ví dụ:
-
$max: Lấy giá trị lớn nhất trong các giá trị tương ứng từ tất cả document trong collection.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", num_tutorial: { $max: "$likes" } } } ])
- Ví dụ:
-
$push: Thêm giá trị vào một mảng trong document kết quả.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", url: { $push: "$url" } } } ])
- Ví dụ:
-
$addToSet: Thêm giá trị vào một mảng trong document kết quả nhưng không bị duplicate- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", url: { $addToSet: "$url" } } } ])
- Ví dụ:
-
$first: Lấy giá trị đầu tiên từ những source document tương ứng với group. Thông thường điều này chỉ có ý nghĩa cùng với một số giai đoạn$sortđược áp dụng trước đó.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", first_url: { $first: "$url" } } } ])
- Ví dụ:
-
$last: Lấy giá trị cuối cùng từ những source document tương ứng với group. Thông thường điều này chỉ có ý nghĩa cùng với một số giai đoạn$sortđược áp dụng trước đó.- Ví dụ:
db.mycol.aggregate([ { $group: { _id: "$by_user", first_url: { $last: "$url" } } } ])
- Ví dụ:
-
Pipeline có nghĩa là khả năng thực hiện một phép toán trên một vài input và sử dụng output đó để là input cho câu lệnh tiếp theo ... MongoDB cũng hỗ trợ khái niệm này trong aggregation. Đây là một tập các giai đoạn và mỗi giai đoạn được lấy làm bộ documents - input và tạo ra tập các document kết quả (hoặc cuối cùng trả về JSON document tại cuối pipeline). Và nó có thể được dùng ở giai đoạn tiếp theo và cứ thế tiếp tục.
-
Các giai đoạntrong aggregation framework:
$project: Được dùng để chỉ định những field lấy ra từ collection$match: Đây là một toán tử để lọc (filter) và do đó nó giảm số lượng được dùng làm input cho giai đoạn tiếp theo (biểu thức theo sau $match có thể được hiểu như là điều kiện lọc)$group: nhóm các phần tử$sort: Sắp xếp các document$skip: skip một số lượng document$limit: giới hạn số documents tìm được$unwind: được dùng để bung những document đang dùng arrays. Khi dùng array, dữ liệu được pre-joined và thao tác này sẽ được hoàn tác với nó để có được document riêng lẻ lần nữa. Do đó với giai đoạn này ta có thể tăng số lượng document cho giai đoạn tiếp theo.
-
-
Là một process để đồng bộ dữ liệu giữa nhiều server.
-
Cung cấp dự phòng và tăng tính khả dụng (avalability) của dữ liệu nhờ việc tạo ra nhiều bản sao của dữ liệu trên các server.
-
Giúp bảo vệ database khỏi sự mất mát ở một server.
-
Giúp recover ngay cả khi gặp lỗi phần cứng hay gián đoạn các service
-
Với các bản sao dữ liệu thì bản có thể dùng để khắc phục sự cố, báo cáo hoặc sao lưu.
-
Ưu điểm:
- Giữ cho dữ liệu được an toàn
- Tính khả dụng cao cho dữ liệu
- Khắc phục sự cố
- Không có downtime khi maintain
- Read scaling (mở rộng việc đọc dữ liệu)
- Replica set không thể nhận ra ở tầng ứng dụng
-
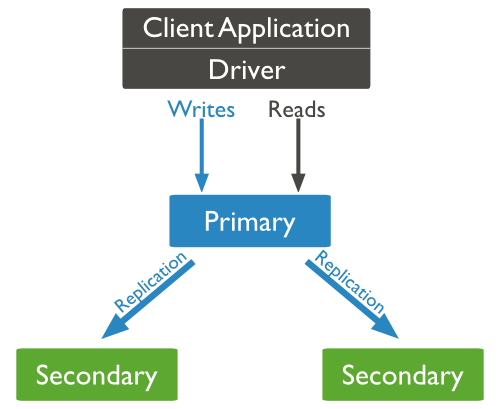
Trong MongoDB thì replication hoạt động bằng cách sử dụng replica set. Nó là một nhóm các mongod instance chứa cùng bộ data set. Có một node là
primary nodeđể nhận tất cả các hoạt động ghi dữ liệu. Còn tất cả các instance còn lại, gọi làsecondary, thực hiện các hoạt động từ primary nên sẽ có cùng data set. Replica set chỉ có duy nhất một primary node.- Replica set là một tập gồm ít nhất 2 node (thường thì 3 node là tối thiểu)
- Trong replica set thì một node là primary còn lại là secondary.
- Tất cả dữ liệu được nhân rộng từ primary về secondary.
- Tại thời điểm chuyển đổi dự phòng tự động (automatic failover) hoặc bảo trì, primary node bị failed, sẽ có một node được bầu lên làm primary mới.
- Sau khi recovery failed node thì nó sẽ join lại replica set và hoặc động như một secondary.
-
Tính năng của replica set
- Một cluster gồm N nodes
- Một node bất kì là primary
- Tất cả write operation đều vào primary
- Automatic failover
- Automatic recovery
- Bầu cử đồng thuận cho primary (consensus election of primary)
-
Cài đặt một replica set
- Chúng ta sẽ chuyển một standalone MongoDB instance sang replica set.
-
Tắt tất cả các MongoDB server đang chạy
-
Chạy MongoDB và chỉ định option --replSet:
mongod --port "PORT" --dbpath "YOUR_DB_DATA_PATH" --replSet "REPLICA_SET_INSTANCE_NAME"- Ví dụ:
mongod --port 27017 --dbpath 'path-to-data' --replSet rs0
- Khởi chạy một mongod instance ở cổng 27017 với tên rs2
- Bây giờ mở terminal và connect tới instance này
- Trong mongo client khởi tạo một replica set bằng lệnh
rs.initiate() - Xem cấu hình replica set bằng lệnh
rs.conf() - Kiểm tra trạng thái của replica set bằng lệnh
rs.status()
-
Thêm member vào repica set
rs.add(HOSTNAME:PORT)- Bạn chỉ có thể add thêm node khi bạn connect đến primary node. Để kiểm tra xem bạn có đang ở primary không thì dùng lệnh
db.isMaster()
-
- Chúng ta sẽ chuyển một standalone MongoDB instance sang replica set.
-
Là một process để lưu trữ dữ liệu trên nhiều máy, và đây là cách MongoDB tiếp cận để đáp ứng như cầu tăng trưởng dữ liệu. Khi dung lượng dữ liệu tăng lên, một máy có thể đáp ứng đủ cho việc lưu trữ cũng như ko thể cung cấp một thông lượng đọc ghi (readable and writeable throughput) chấp nhận được. Sharding giải quyết vấn đề bằng cách horizontal scaling. Với sharding thì bạn có thể thêm nhiều máy để hỗ trợ việc tăng trưởng dữ liệu cũng như nhu cầu đọc ghi dữ liệu.
-
Tại sao phải sharding?
- Trong replication, tất cả hoạt động ghi đều qua master node.
- Latency sensitive queries vẫn đi qua master
- Một replica giới hạn 12 nodes
- Memory ko đủ để chứa data set quá lớn
- Local disk cũng ko đủ lớn
- Vertical scaling thì lại đắt đỏ
-
Sharding trong MongoDB
- https://medium.com/@dongnguyenltqb/x%C3%A2y-d%E1%BB%B1ng-c%E1%BB%A5m-c%C6%A1-s%E1%BB%9F-d%E1%BB%AF-li%E1%BB%87u-b%E1%BA%B1ng-mongodb-building-database-clusters-with-mongodb-82ecb19912ec
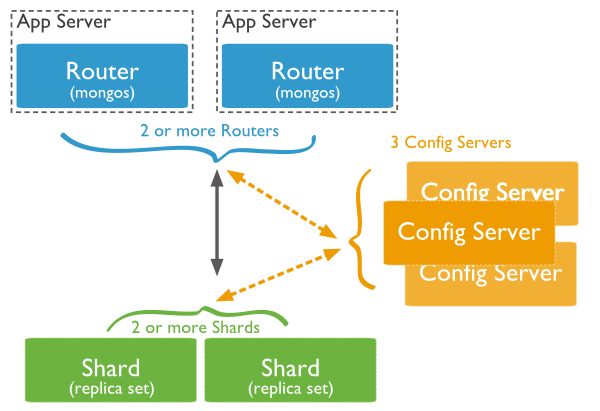
- Trong mô hình trên, có 3 thành phần chính:
- Shards: được dùng để lưu trữ dữ liệu. Chúng cung cấp high availability và đồng nhất dữ liệu. Trong môi trường production thì mỗi shard là một replica set.
- Config Servers: lưu metadata của cluster. Dữ liệu này chứa mapping giữa data set của cluster tới shard. Query router sẽ dùng những thông tin để gửi các hành động (operations) đến shard cụ thể. Ở môi trường production thì sharded cluster có chính xác 3 config servers.
- Query Routers: cơ bản là những mongo instance, giao tiếp với ứng dụng client, và hoạt động trực tiếp tới shard thích hợp. Query router xử lí và đưa operation đến shard và sau đó trả về kết quả cho client. Một shared cluster có thể chứa một hoạt nhiều query router để chia tải request cho client. Một client gửi request đến một query router. Thường thì một shared cluster sẽ có nhiều query routers.
-
Để tạo một bản backup cho MongoDB thì chúng ta dùng lệnh
mongodump. -
Để sử dụng thì bạn chỉ cần mở terminal và đi đến thư mục bin của mongodb rồi gõ
mongodump= Lệnh này sẽ kết nối đến server mongo đang chạy và backup tất cả dữ liệu vào thư mục /bin/dump/ -
Danh sách các options của lệnh
mongodump:mongodump --host HOST_NAME --port PORT_NUMBER: dùng để backup tất cả các db của mongo instance được chỉ địnhmongodump --dbpath DB_PATH --out BACKUP_DIR: dùng để backup db được chỉ định trong db path.mongodump -collection COLLECTION --db DB_NAME: dùng để backup collection trong db được chỉ định
-
Restore dữ liệu:
mongorestore
mongostat: kiểm tra trạng thái của tất cả các mongo instance đang chạy và trả về bộ đếm các hoạt động của db bao gồm insert, query, update, delete, cursor. Nó cũng hiển thị các trường hợp lỗi và lock percentage của bạn. Có nghĩa là bạn có thể đang gặp các vấn đề về running low on memory, hitting write capacity hoặc có vấn đề về hiệu năng.mongotop: Dùng để track và report hoạt động đọc và ghi của MongoDB instances trên một tập collection. Mặc định thì mongotop trả về thông tin mỗi giây. Bạn có thể xem được mọi thứ có đúng như dự tính ko, bạn có ghi có nhiều cùng lúc không, bạn có đọc quá thường xuyên từ disk không, hay có đang vượt quá dung lượng đc thiết lập ko.- Có thể dùng
mongotop <time-repeat>để thay đổi thời gian mặc định.
- Có thể dùng