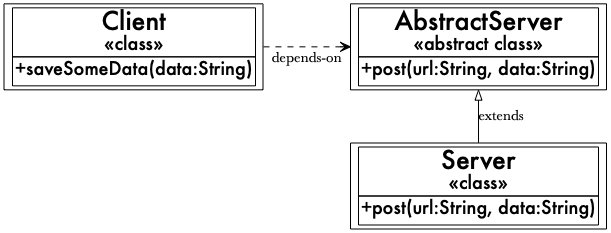
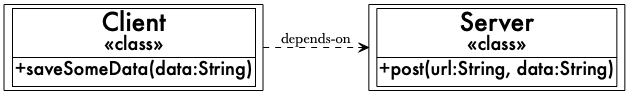2019年11月11日
最近、SOLIDの原則について考えていて、その有用性に疑問を感じている。 SOLIDの原則は曖昧で、範囲が広すぎて、混乱を招き、場合によっては完全に間違っている。しかし、これらの原則の動機は正しい。問題は、ニュアンスの異なる概念を簡潔な文に落とし込もうとすることにあって、翻訳の過程で価値の大部分を失っているのだ。 これはプログラマーを間違った道へと導いてしまう(私にとっては確かにそうだった)。
おさらいとして、SOLIDの原則は以下の通りである:
- 単一責任原則
- オープン/クローズの原則
- リスコフの置換原理
- インターフェース分離の原則
- 依存関係の逆転原理
今回は「単一責任原則」を取り上げ、4回にわたって他の原則に取り組む。
ウィキペディアには 次のように書かれている。
つまり、ソフトウェアの仕様のひとつに対する変更だけが、そのクラスの仕様に影響を与えることができる。
これはかなり曖昧だ。「仕様」とは何だろう? 私はこの23年間、仕様の定まったソフトウェアに携わったことがない。 そして、ここでの「影響」とは何を意味するのか?
ウィキペディアの記事では、「例」のセクションで説明している(強調は原文のまま):
マーティン[この言葉を作ったロバート・マーティン 1 ]は、責任とは変更理由であると定義している。
というのも、 すべて のコードには、バグを修正するか機能を追加するかという、少なくとも 2つ の変更理由があるからだ。では、それらが別の理由と見なされないのであれば、「理由」とは何なのか?
そこが曖昧なので、コードレビューに単一責任原則を適用するとだいたい泥沼化する。というのも、誰もがレビュー中のコードの質ではなく、原則をどう解釈するかについて話し始めるからだ。
とはいえ、コードが持つべき仕事/事柄/責任は1つだけというのは正しい 気がする 。 このRailsコントローラを考えてみよう:
class WidgetsController < ApplicationController
def create
@widget = Widget.create(widget_params)
if @widget.valid?
redirect_to :index
else
render :new
end
end
def widget_params
params.require(:widget).permit(:name, :price)
end
endこれは非常にバニラな実装で、新しいウィジェットが有効であればデータベースに保存し、有効でなければ、バリデーションの問題を修正するためにユーザーをフォームに送り返す。
「バグフィックスと新機能」という変更理由はさておき、このクラスには変更する理由がたくさんありそうだ。 ウィジェットを要求するために必要なパラメータを追加するかもしれない。 ウィジェットが作成されたときに、ユーザを別の場所にルーティングする必要があると判断するかもしれない。 ウィジェットが作成されるたびに、管理者にメールを送信する必要があるかもしれない。つまり、このコードが単一責任原則に違反していることは明らかであり、したがって悪いことであり、変更されるべきなのだ。そうだろう?
ここでそれを受け入れるのは難しい。 このコードは、Railsが推奨するコードの書き方の規範になっているだけでなく、短く、直接的で、要点がまとまっている。 もちろん、時間が経てばこのコントローラにさらにコードを追加することもできるし、コントローラが大きく複雑になることもあるだろう。しかし、このコードの変更理由が 正確に1つ であるべきだとか、修正が必要だと言うのだろうか?それは意味がない。
科学のために、このコードを変更して責任の数を減らしてみよう。
class WidgetsController < ApplicationController
def create
@widget = WidgetCreator.create(params)
WidgetRouter.route(self, @widget)
end
end
class WidgetCreator
def self.create(params)
Widget.create(params.require(:widget).permit(:name, :price)
end
end
class WidgetRouter
def self.route(controller, widget)
if widget.valid?
controller.redirect_to :index
else
controller.render :new
end
end
end各クラスの責任は確かに軽くなり、変わる理由も少なくなった。しかし、これを改善と見るのは難しい。確かに、ウィジェットの作成方法が複雑になれば、別のクラスを持つことに価値があるかもしれない。また、作成時のルーティングが多くの微妙なルールに左右されるのであれば、それを抽出することに価値があるかもしれないが、今回はそうではない。決してこのコードが優れているわけではない。
このことが私に教えてくれるのは、単一責任原則はそのままでは役に立たず、盲目的に固執すれば、解決しようとしている以上の問題を引き起こすかもしれないということだ。
とはいえ、単一責任原則の意図は正しい。それは、モジュールの要素がどの程度まとまっているかという 凝集性 についての方向性を与えようとしているのである。 問題は、結束はそれほど単純明快ではないということだ。
凝集性 とは、コンピュータ・サイエンスで長い間議論されてきた概念で、要素(コードの一部)が一緒になっているモジュール(コードのグループ化を意味する)は、要素が一緒になっていないモジュールよりも保守性が高く、理解しやすいというものだ。
凝集性だって単一責任原則と同様に曖昧だが、 原則 としては提示されておらず、遵守しなければならない客観的な尺度としても提示されていない。
強力な規定措置がないということは、責任の数を数えるのをやめて、今あるコードとそれに加えたい変更について話し始めることができるということだ。 元のコントローラに対する2つの変更を見てみよう。これらの変更はどちらも単一責任の原則に違反することになる。しかし、クラスの凝集性に重大な影響を与えるのは1つだけだ。
最初の例では、ウィジェットが作成されるたびにメールを送信するコードを追加する。
class WidgetsController < ApplicationController
def create
@widget = Widget.create(widget_params)
if @widget.valid?
WidgetMailer.widget_created(@widget) # <------
redirect_to :index
else
render :new
end
end
def widget_params
params.require(:widget).permit(:name, :price)
end
endウィジェットの作成とそれに関するEメールの送信は、一緒にあるべきもののように思えるので、この変更はこのクラスのまとまりに実質的な影響を与えないと主張したい2.
ウィジェットを保持するテーブルのデータベース統計を記録する、別の変更を見てみよう:
class WidgetsController < ApplicationController
def create
@widget = Widget.create(widget_params)
if @widget.valid?
DatabaseStatistics.object_created(:widget) # <-----
redirect_to :index
else
render :new
end
end
def widget_params
params.require(:widget).permit(:name, :price)
end
endコントローラーはデータベースとは何の関係もない。だから、この変更は、私たちがこの変更に疑問を持つのに十分なほど、クラスのまとまりを弱めるように感じる。
しかし、どちらの場合も単一責任原則に違反している。 このことは、凝集性の概念を単一責任原則に当てはめることが絶対に間違っていることを物語っている。
私からのアドバイスだ: 単一責任について話すのをやめて、凝集性の話を始めよう。
次回は「オープン/クローズの原則」を取り上げる。この原則は、全く役に立たないほど混乱している。
Footnotes
-
ロバート・マーティン、別名 "アンクル・ボブ "は、私の個人的価値観と矛盾する発言をオンライン上で行っている。 とはいえ、彼はソフトウェアとオブジェクト指向設計の世界で影響力を持っており、彼のアイデアは多くの開発者によって教えられているため、彼の考えを批判することには価値があるのだ。アンクル・ボブのオンライン上での行動についてもっと知りたいのであれば、Twitterで彼を見つけるのがよいだろう。 ↩
-
また、この変更がリファクタリング後のバージョンでどのように物事を複雑にしていたかにも注目すべきだ。このコードを
WidgetRouterに追加する必要があり、それは非常に間違っていると感じられるはずであり、したがって、この1行のコードを追加するためには、より大規模なリファクタリングが必要になるのだ。 ↩