-
-
Save onionmk2/b6b5ed19c51a2360e8841498a4ba2002 to your computer and use it in GitHub Desktop.
Revisions
-
matarillo revised this gist
Feb 19, 2025 . 4 changed files with 4 additions and 4 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -4,7 +4,7 @@ https://naildrivin5.com/blog/2019/11/14/open-closed-principle-is-confusing-and-w 2019年11月14日 [SOLID](https://en.wikipedia.org/wiki/SOLID) 原則は、当初考えられていたほど「ソリッド(確固としたもの)」ではないことに気づきつつあるのである。[前回の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) では、単一責任原則の問題点を概説したが、今回は5つの原則の中で最も理解しづらいオープン/クローズドの原則について述べたいと思う。 この原則は、ソフトウェアは「拡張に対してオープンであり、修正に対してクローズドであるべき」というものである。この要約は非常にわかりづらく、深く掘り下げてみると悪いアドバイスばかりであった。この原則は完全に無視すべきだ。その理由を見ていこう。 This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -4,7 +4,7 @@ https://naildrivin5.com/blog/2019/11/18/liskov-substitution-principle-is-not-a-d 2019年11月18日 [元の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) で述べたように、私はSOLID原則が...思われるほどソリッド(確固としたもの)ではないことに気づいている。最初の投稿では、単一責任原則に私が見る問題点を概説した。2番目の投稿では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。さて、Liskov置換原則について話そう。これは、結局のところ、設計のアドバイスではないのだ。 この原則は、「プログラム内のオブジェクトは、プログラムの正しさを変えることなく、そのサブタイプのインスタンスと置き換え可能であるべきだ」と述べている。これを理解するには、「プログラムの正しさ」が何を意味するのかを知る必要がある。 This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -2,7 +2,7 @@ 2019年11月21日 元の投稿で述べたように、私はSOLID原則が...思われるほどソリッド(確固としたもの)ではないことに気づいている。その投稿では、単一責任原則に私が見る問題点を概説した。2番目の投稿では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。3番目の投稿では、Liskov置換原則が間違った問題に焦点を当てすぎていて、実際には使えるデザインのガイダンスを与えていないことについて話した。 今回は、インターフェース分離原則について話したい。これは、結合の問題に対して非常に奇妙な解決策を処方するものだ。実際には、結合 _と_ 凝集性について直接話し合い、どちらか一方に最適化しすぎないように注意すべきなのだ。 This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -4,7 +4,7 @@ https://naildrivin5.com/blog/2019/12/02/dependency-inversion-principle-is-a-trad 2019年12月2日 [元の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) で述べたように、私はSOLID原則が...思われるほどソリッド(確固としたもの)ではないことに気づいている。その投稿では、単一責任原則に私が見る問題点を概説した。 [2番目の投稿](https://naildrivin5.com/blog/2019/11/14/open-closed-principle-is-confusing-and-well-wrong.html) では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。 [3番目の投稿](https://naildrivin5.com/blog/2019/11/18/liskov-substitution-principle-is-not-a-design-principle.html) では、Liskov置換原則が間違った問題に焦点を当てすぎていて、実際には使えるデザインのガイダンスを与えていないことについて話した。 [4番目](https://naildrivin5.com/blog/2019/11/21/interface-segreation-principle-is-unhelpful-but-inoffensive.html) は、インターフェース分離原則が結合の問題へのアプローチとして適切ではないことについてだ。 さて、最後の原則、依存性逆転の原則に移ろう。これは、「2000年代のJavaがすべてのコードをXMLで書くことと同一視される理由の原則」とも呼べるものだ。この原則は、コードは具体ではなく抽象に依存すべきだと述べている。原則であるため、 _すべて_ のコードが抽象に依存すべきだという含意がある。いやいや、そうあるべきではない。抽象に依存することにはコストがかかるが、この原則はそれを大いに無視している。それを見てみよう。 -
May 27, 2024 . 1 changed file with 243 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,243 @@ # 依存性逆転の原則...はトレードオフだ (SOLIDはソリッドではない) https://naildrivin5.com/blog/2019/12/02/dependency-inversion-principle-is-a-tradeoff.html 2019年12月2日 [元の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) で述べたように、私はSOLID原則が...思われるほどソリッド(堅牢)ではないことに気づいている。その投稿では、単一責任原則に私が見る問題点を概説した。 [2番目の投稿](https://naildrivin5.com/blog/2019/11/14/open-closed-principle-is-confusing-and-well-wrong.html) では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。 [3番目の投稿](https://naildrivin5.com/blog/2019/11/18/liskov-substitution-principle-is-not-a-design-principle.html) では、Liskov置換原則が間違った問題に焦点を当てすぎていて、実際には使えるデザインのガイダンスを与えていないことについて話した。 [4番目](https://naildrivin5.com/blog/2019/11/21/interface-segreation-principle-is-unhelpful-but-inoffensive.html) は、インターフェース分離原則が結合の問題へのアプローチとして適切ではないことについてだ。 さて、最後の原則、依存性逆転の原則に移ろう。これは、「2000年代のJavaがすべてのコードをXMLで書くことと同一視される理由の原則」とも呼べるものだ。この原則は、コードは具体ではなく抽象に依存すべきだと述べている。原則であるため、 _すべて_ のコードが抽象に依存すべきだという含意がある。いやいや、そうあるべきではない。抽象に依存することにはコストがかかるが、この原則はそれを大いに無視している。それを見てみよう。 ここで批判を完結させて、単に「必要のない柔軟性を追加するな」と言うこともできるかもしれない。しかし、これが原則だと考えられている背景は興味深いと思う。第一原理から深く設計について考えた人から出たものではないからだ。代わりに、JavaとC++がオブジェクト指向を実装するために選択した方法のいくつかの制限に関連した防御メカニズムなのだ。 [Wikipediaの記事](https://en.wikipedia.org/wiki/Dependency_inversion_principle) から引用すると: > 多くの単体テストツールがモックを実現するために継承に依存しているため、クラス間の一般的なインターフェースの使用(一般性を使用するのが理にかなっているモジュール間だけでなく)がルールになった。 こうして、大規模なJavaプロジェクトになぜ依存性の注入が非常に多いのか、そして主にJavaで作業している場合になぜ依存性逆転が設計原則のように感じられるのかがわかり始める。 ## 依存性の注入は後付けの設定だ 私は、キャリアの最初の3分の2をJavaで過ごした。私が携わった最も複雑なJavaアプリケーションは、依存性逆転の原則を大いに利用していた。すべてのクラスは、そのクラスを必要とするものがインターフェースにのみ依存できるように、別々のインターフェースと別々の実装を持たなければならなかった。すべての、単一の、クラスだ。 `ReturnProcessor`というクラスを作る必要がある場合、`ReturnProcessor`をインターフェースにし、`ReturnProcessorImpl`というクラスで実装する。いつでもどこでも、だ。その理由は、実際には設計の純粋さとかそういったものではなかった。Javaでのモックとユニットテストに対処するためだったのだ。 仕事をするために`ReturnProcessor`を必要とする`ShipmentIntake`クラスを考えてみよう。依存性逆転などを考えずに、次のように書くかもしれない。 ```java public class ShipmentIntake { public processShipment(Shipment shipment) { ReturnProcessor returnProcessor = new ReturnProcessor() returnProcessor.process(shipment) // ... } } ``` このコードをテストするには、テストの一部として実際の`ReturnProcessor`の実行を許可するか、それをモックする必要がある。依存関係をモックすることは非常に一般的で、非常に便利だ。`ReturnProcessor`が実際のWebサービスに多数のHTTPコールを行うとしよう。テストでそれらのHTTPコールを行いたくないので、それを避けるために`ReturnProcessor`をモックする。 問題は、このコードの書き方では、`ReturnProcessor`を簡単にモックできないことだ。Javaでは、`new`はオブジェクトのメソッド呼び出しではないからだ。それは特別な形式であり、モックの`ReturnProcessor`を返すようにその動作を変更することはできない。 この制限を回避するために、`ReturnProcessor`を他の誰か( _依存性を注入する_ プロセスと呼ばれる)によって`ShipmentIntake`に与えることを許可する。これを行う最も簡単な方法は次のようになる。 ```java public class ShipmentIntake { private ReturnProcessor returnProcessor; public ShipmentIntake(ReturnProcessor returnProcessor) { this.returnProcessor = returnProcessor; } public processShipment(Shipment shipment) { this.returnProcessor.process(shipment) // ... } } ``` これにより、モック化された動作を持つ実際の`ReturnProcessor`のサブクラスを作成でき、それをテストで使用できる。例えば: ```java ReturnProcessor mockReturnProcessor = createMock(ReturnProcessor.class) // or whatever ShipmentIntake shipmentIntake = new ShipmentIntake(mockReturnProcessor) ``` ただし、これでは問題は完全には解決しない。Javaでは、クラスがサブクラスを持つことができない、または特定のメソッドがオーバーライドできないことを示すことができる。そのようにされている場合、テスト用のサブクラスを作成することはできない。 _それ_ を回避するために、`ShipmentIntake`が依存するインターフェースを作成し、実際の`ReturnProcessor`がそれを実装するようにする。モックの`ReturnProcessor`はもはやサブクラスである必要はない。インターフェースを実装すればよいのだ。 _それ_ は次のようになる。 ```java public interface ReturnProcessor { public void process(Shipment shipment) } public class ReturnProcessorImpl implements ReturnProcessor { public void process(Shipment shipment) { // ... } } public class ShipmentIntake { private ReturnProcessor returnProcessor; public ShipmentIntake(ReturnProcessor returnProcessor) { this.returnProcessor = returnProcessor; } // ... } ``` 私たちは今、「依存性を逆転」させた。なぜなら、`ShipmentIntake`はもはや具体的な実装に依存せず、代わりに一般的なインターフェースに依存し、そのインターフェースの任意の実装を提供できるからだ。 問題は、これは本当にユニットテストの問題に対処するためにのみ必要だったが、結局はこれを _どこでも_ やらなければならなくなり、最終的にはこれが単に「良いオブジェクト指向設計」だと決めつけてしまうことだ。元々解決しようとしていた問題ではないにもかかわらず、だ。 もちろん、このパターンはまた、これらすべての依存関係を結びつける新しいコードが必要になるという問題も生み出す。どこかで、`ShipmentIntake`に使用する`ReturnProcessor`の実装を知っているものが必要だ。昔は、これは巨大なXMLファイルだったが、最近では、ソースコードにアノテーションを追加して、それを実現できる。 しかし、オープン/クローズド原則の投稿で議論したように、この追加された柔軟性は無料ではない。コストがかかる。それは、システム全体を理解しにくくすることだ。なぜなら、`ShipmentIntake`のソースコードを見ても、実行時にどのオブジェクトが使用されるかがわからなくなるからだ。実装を入れ替える _必要_ がなければ、これは何の利点もない不要な柔軟性だ。 覚えておいてほしいのは、これを導入したのは、コードを「より良く」するためではなく、Javaでのテストの方法に関する問題を解決するためだということだ。Rubyを使用していれば、元の問題は発生しなかっただろう。Rubyでの元の`ShipmentIntake`は次のようになる。 ```rb class ShipmentIntake def process_shipment(shipment) return_processor = ReturnProcessor.new return_processor.process(shipment) # ... end end ``` `new`はオブジェクト(つまり、クラスでもある`ReturnProcessor`オブジェクト)に対して呼び出されるメソッドであり、Rubyは任意のメソッドの動作を動的に変更できるため、依存関係を逆転させる必要なく(Rubyにはインターフェースがないことを念頭に置いて)、テスト中に`ReturnProcessor.new`がモックオブジェクトを返すように簡単に設定できる。 一部の開発者はこれを好まないが、繰り返しになるが、これはトレードオフだ。依存関係を逆転させてそれらを注入可能にすると、新しい問題が生じる。つまり、クラスは単純化されるかもしれないが、システムはより複雑になるのだ。これは本当のトレードオフだ! ## システムの複雑さは重要だ `ReturnProcessor`のRuby版は、シンプルなAPIを持っている。引数なしで作成でき、`shipment`を受け取る単一のメソッドがある。もしそのコラボレーター(`ReturnProcessor`など)を注入できるようにすると、次のように、リターンプロセッサーへの依存を公開するため、そのAPIはより複雑になる。 ```rb class ShipmentIntake def initialize(return_processor = ReturnProcessor.new) @return_processor = return_processor end def process_shipment(shipment) @return_processor.process(shipment) # ... end end ``` 大したことではないと思うかもしれないが、これは実際には重要だ。`ShipmentIntake`が出荷を処理することだけに関するデザインから、「リターンプロセッサーで出荷を処理する」ことに関するデザインに変わったのだ。`ShipmentIntake`のクライアントは、リターンプロセッサーについて知る必要があるだろうか? `ShipmentIntake`が何に使用されるかを知らずにその質問に答えるのは難しい。異なる状況で異なるリターンプロセッサーを使用する必要がある場合は、はい、`ReturnProcessor`を注入できるようにすべきだ。しかし、この柔軟性が必要ない場合はどうだろう? もしその柔軟性が必要 _ない_ のであれば、それを追加することを良いこととは見なしがたい。クラスのAPIを必要以上に大きくしてしまったのだ。そして、オープン/クローズド原則の投稿で議論したように、不必要な柔軟性を持つクラスは、実行時に正確にどのオブジェクトが使用されたかを追跡しなければならないため、システム全体の理解を難しくする。 では、いつクラスを抽象に依存するように設計 _すべき_ だろうか? テストの問題を除けば(Javaでは、依存関係を注入するためのパブリックAPIを作成することなく、実際には別の方法で解決できる)、特定のオブジェクトの作成が複雑な場合、依存関係を外部化することは有用に思える。 ## オブジェクトの構築と使用の分離 これまでの例では、コンストラクタに何も渡さずにオブジェクトを作成していた。しかし、オブジェクトを構築するために情報が必要な場合はどうだろう? 例えば、`ReturnProcessor`がHTTPコールを行う場合、URLや認証情報など、それを行う方法に関するかなりの情報が必要になるかもしれない。 `ShipmentIntake`が`ReturnProcessor`のインスタンスを作成する責任を持つ場合、問題が発生するかもしれない。`ShipmentIntake`は`ReturnProcessor`を作成するためのすべての設定値を知っている必要があるか、それ自体も _その_ コンストラクタのどこかから設定を与えられる必要があり、そうするとあちこちに設定が渡されることになる。 1つの解決策は、すべてのクラスにグローバルな設定オブジェクトを提供し、必要なときに必要なものを取り出すことだ。 ```java public class ShipmentIntake { public ShipmentIntake(GlobalConfig config) { this.returnProcessor = new ReturnProcessor( config.returnPartner.getUrl(), config.returnPartner.getUsername(), config.returnPartner.getPassword() ); } } ``` これは、カプセル化を維持する。`ShipmentIntake`のユーザーは、完全に機能するオブジェクトを取得するために`new ShipmentIntake(config)`を呼び出すだけでよく、それを作成するために`ShipmentIntake`がどのように実装されているかを知る必要はない。しかし、すべてのクラスがどこでもすべての設定にアクセスできるため、不快な結合が生じる。これにより、おそらくそうあるべきではないのに、2つのクラスが同じ設定オプションに依存する状況が生まれ、システムが不必要に変更しにくくなる可能性がある。アプリケーションの設定は必ずしも凝集性が高くないので、それをあちこちに増殖させないようにするのは理にかなっている。 依存性逆転の原則に従えば、どのクラスも依存関係をインスタンス化する必要はない。代わりに、どこか別の場所からそれらの依存関係が提供される。その別の場所とはどこだろう? どこかでオブジェクトの作成方法と、どのオブジェクトをどの他のオブジェクトに渡すかを知っている必要がある。このオブジェクトの _配線_ は設定の一形態であり、2000年代のJavaでは、XMLファイルで行われていた。今日では、アノテーションを使って暗黙的に行われているが、ScalaやGoなどの言語では、次のようにコードで行われる。 ```java // Somehwere deep and dark that is allowed to have a bunch of // coupling so that most objects don't have to GlobalContext globalContext = new GlobalContext(); globalContext.loadDefaultsFromEnvironment(); globalContext.put( "ReturnProcessor", new ReturnProcessor( globalContext.get("returnPartner.url"), globalContext.get("returnPartner.username"), globalContext.get("returnPartner.password") ) globalContext.put( "ShipmentIntake", new ShipmentIntake(globalContext.get("ReturnProcessor") ) ``` この`GlobalContext`には、システムが必要とする _すべて_ のオブジェクトのインスタンスがあり、それらはすべて設定されて準備ができている。これは基本的にSpring Frameworkの仕組みだ(ただし、すべての配線を設定するのはそれほど厄介ではない)。 このように構築されたアプリケーションには利点が _ある_ 。日々のコードは、オブジェクトのメソッドを呼び出すだけで構成され、オブジェクトの設定や作成に手を加える必要はほとんどない。しかし、このようなシステムのデバッグは楽ではない。アプリケーションの「配線」部分は非常に複雑になる可能性があり、それを正しく行うのは必ずしも簡単ではない。 複雑なアプリケーションでは、コードのかなりの部分がこの配線になることがあり、それが正しいことを確認するために、書き込み自体の統合テストが必要になる。アプリケーションが暗黙的に配線されている場合(現代のSpringアプリケーションのように、配線を行う実際のコードや設定がない場合)、実行時に実際にどのオブジェクトが使用されているかを把握するのは非常に難しい。 Ruby on Railsアプリケーションでは、この設定の問題をいくつかの方法で解決している。 一般的なパターンは、クラスが初期化時に設定される明示的な設定オブジェクトを公開することだ。この設定は、そのクラスのインスタンスを作成するたびに使用されるため、すべてのコードは単に`ReturnProcessor.new`と書くことができ、`ReturnProcessor`内であらかじめ設定された設定がクラスの設定に使用される。 Railsでは、`config/initialzers`のファイルはアプリの起動時に実行されるので、次のようなことを行うかもしれない。 ```rb # config/initializers/return_processor.rb ReturnProcessor.configure do |config| config.url = ENV["RETURN_PARTNER_URL"] config.user = ENV["RETURN_PARTNER_USERNAME"] config.pass = ENV["RETURN_PARTNER_PASSWORD"] end ``` オブジェクトのコンストラクタであるべきものの設定オブジェクトを外部化するのは奇妙に思えるかもしれないが、これは問題に対する良い解決策だ。アプリケーションコードはすべて、必要なときに必要なオブジェクトを作成でき、オブジェクトが重要な設定を必要とする場合は、それが他の場所で処理される。 _実際の_ オブジェクトを事前に作成する強い必要性はない。 もう1つのパターンは、次のように、イニシャライザで単一のグローバルなオブジェクトインスタンスを作成することだ。 ```rb # config/initializers/return_processor.rb RETURN_PROCESSOR = ReturnProcessor.new( ENV["RETURN_PARTNER_URL"], ENV["RETURN_PARTNER_USERNAME"], ENV["RETURN_PARTNER_PASSWORD"] ``` そして、クラスは`ReturnProcessor`が必要な場合、事前に設定されたグローバルインスタンス`RETURN_PROCESSOR`を使用することを知っている。 最後の2つは嫌な感じがするかもしれないが、問題が本当に存在するのか、それとも単に純粋性に関連しているだけなのか、正直に自問してみよう。はい、グローバル変数は問題になる可能性があるが、アプリケーションに作成が難しいオブジェクトが少ししかない場合、これはあちこちに依存性注入を設定するよりも良い解決策ではないだろうか? 重要なのは、これはトレードオフだということだ。常に依存関係を逆転させ、常に依存性注入を使用することを示す「原則」は、すべての状況に対して常に正しいアドバイスではない。コードの振る舞いを非常に明示的にし、何が何を使っているかを直接見ることの方が価値がある場合、抽象化された依存性注入は問題になるだろう。一方、システム全体の理解度を犠牲にしてでも、すべてのクラスの設計に一貫性を持たせたい場合は、それでもよい。 トレードオフを理解し、SOLID原則にこだわらずに、自分のニーズと価値観に基づいて選択すること! 単に「抽象に依存する」だけでは、全体像を見ていないことになる。設計作業をしているのではなく、アプリケーションやチームの成功にとって重要なトレードオフを見逃すことになる。 私にとって、必要なものを構築し、必要になったときに柔軟性を追加するのが、必要になるかもしれないからというだけで柔軟性を追加するよりも常に良い。そして、テスト可能であるためにクラスを柔軟にする必要があるなら...素晴らしい! ただそう言ってほしい! 私のアドバイス: **必要であれば依存関係を注入し、なぜそうするのかについて正直であること。そうでなければ、必要のない柔軟性を追加しないこと。** -
May 27, 2024 . 1 changed file with 145 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,145 @@ # インターフェース分離原則は役に立たないが無害だ (SOLIDはソリッドではない) 2019年11月21日 元の投稿で述べたように、私はSOLID原則が...思われるほどソリッド(堅牢)ではないことに気づいている。その投稿では、単一責任原則に私が見る問題点を概説した。2番目の投稿では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。3番目の投稿では、Liskov置換原則が間違った問題に焦点を当てすぎていて、実際には使えるデザインのガイダンスを与えていないことについて話した。 今回は、インターフェース分離原則について話したい。これは、結合の問題に対して非常に奇妙な解決策を処方するものだ。実際には、結合 _と_ 凝集性について直接話し合い、どちらか一方に最適化しすぎないように注意すべきなのだ。 Wikipediaの記事には次のように書かれている。 > \[インターフェース分離の原則 (ISP)\] は、非常に大きなインターフェースを、より小さく、より具体的なものに分割し、クライアントが関心を持つメソッドについてのみ知る必要があるようにする...ISPは、システムを分離された状態に保ち、リファクタリング、変更、再デプロイを容易にすることを目的としている。 _これ_ はかなり合理的に思える。しかし、原則として述べられているのは、「**クライアントは**、使用しないメソッドに依存することを**強制されるべきではない**」(強調は私による)とある。 まず、Rubyのような動的プログラミング言語は、この原則に自動的に準拠していると言ってよい。なぜなら、クライアントが依存しているものの定義は、クライアントが使用しているものだからだ。Rubyは型を定義しないので、ルーチンに渡すオブジェクトがそのルーチンが呼び出すメソッドに応答する限り、コードは「機能する」 [^1] 。 [^1]: もちろん、Rubyのような言語では、この原則に従うことは**不可能**だとも言える。なぜなら、Rubyでは、プライベートメソッドやインスタンス変数を含め、いつでも好きなメソッドを呼び出すことができるからだ。結論としては、Rubyistにとってこの原則は無意味だということだ。 したがって、JSやRubyのような動的言語で作業している人にとって、この原則は述べられているとおり完全に無意味だ。 とはいえ、Wikipediaの詳細では、別の問題と解決策が提示されている。つまり、クラスにはメソッドを多く含めるべきではない、というものだ。これは、先に話した凝集性に関係するが、同時に別のコアコンセプト、つまり _結合性_ にも関係し始める。 ## ひょっとすると、ひょっとすると、ひょっとすると...実際には結合性に関するものなのかもしれない。 [結合性](https://en.wikipedia.org/wiki/Coupling_(computer_programming)) とは: > ...ソフトウェアモジュール間の相互依存の度合い。2つのルーチンやモジュールがどれだけ密接に接続されているかを測る尺度... 密結合のコード、つまり多くの相互依存関係を持つコードは、疎結合のコードよりも悪いと通常考えられている。Wikipediaでは、密結合コードの欠点を次のように概説している。 > * 1つのモジュールを変更すると、通常、他のモジュールにも変更の波及効果が生じる。 > * モジュール間の依存関係が増えるため、モジュールの組み立てにより多くの労力や時間を要する可能性がある。 > * 特定のモジュールは、依存するモジュールを含めなければならないため、再利用やテストが難しくなる可能性がある。 これらはすべて正当な指摘だ。しかし、この原則が求めるような極端なことをすると、トレードオフが生じる。 _分離された_ システムは、個々の部分がシンプルであっても、理解するのが難しい場合がある。密結合で _凝集性の高い_ コードは、分離されたコードよりもはるかに理解しやすい。 実際、結合性は、ほとんど常に凝集性と一緒に語られる。そこには緊張関係があるからだ。コードを分離したいが、同時に凝集性も高めたい。両方を同時に実現することはできない。バランスを取る必要があり、「常に分離せよ」というアドバイスではそのバランスを見つけることはできない。 ## 設計とは、凝集性と結合性のバランスを取ることだ (原則に盲目的に従うことではない) 例を挙げて、分離を過度に重視すると設計が悪くなる可能性があることを見てみよう。データベース内のウィジェットに関するデータにアクセスするクラスを考えてみる。 ```java public class WidgetRepository { public Set<Widget> find(String query) { // ... } public Widget load(int id) { // ... } public void save(Widget w) { // ... } } ``` このインターフェースには多くの凝集性がある。ウィジェットの検索、ロード、保存はかなりうまく組み合わさっている。しかし、`WidgetRepository`に依存しているにもかかわらず、これらのメソッドの一部しか呼び出さないクラスは、技術的には「使用しないメソッドに依存することを強制されている」ことになる。 この解決策は、実際のプロジェクトに適用されているのを見たことがある。それは、すべてのメソッドを独自のインターフェースにするというものだ。 ```java public interface WidgetLoader { pulbic Widget load(int id); } public interface WidgetSaver { public void save(Widget widget); } public interface WidgetFinder { public Set<Widget> find(String query); } public class WidgetRepository implements WidgetLoader, WidgetSaver, WidgetFinder { // ... } ``` これは、述べられているインターフェース分離原則に、あらゆる面で準拠している。クライアントは、使用しないメソッドに依存する必要はない。`find`を呼び出すだけでよければ、`WidgetFinder`に依存する。`save`も呼び出す必要がある場合は、`WidgetSaver`にも依存する。 これは、特にプロジェクト全体に広く適用する場合(原則ではそうすべきだと言っている!)、良い設計ではない。これでは、命名が爆発的に増え、凝集性のある概念を持たない大量のオブジェクトが生まれてしまう。しかし、SOLIDの原則に違反することなく、分離を達成できるのだ! とはいえ、インターフェースは、結合性と凝集性を評価するためのレンズになるので、それを見てみよう。 ## インターフェースは、結合性と凝集性の物語を語る 在庫が少なくなっているすべてのウィジェットを再発注する必要があるとしよう。そのロジックは、数量が10未満のすべてのウィジェットをデータベースから検索し、フルフィルメントプロバイダにAPIコールを行うというものだ。 これを`WidgetRepository`に追加してみよう。 ```java public class WidgetRepository { public void reOrderWidgets() { for (Widget w: this.find("quantity < 10")) { // call the fulfillment API } } public Set<Widget> find(String query) { // ... } public Widget load(int id) { // ... } public void save(Widget w) { // ... } } ``` これは理想的ではないように思える。ウィジェットの再発注は、ウィジェットのデータベースへのアクセスとあまり関係がないので、インターフェースの凝集性が低くなる。また、`WidgetRepository`の利用者は、ウィジェットを再発注できるようになるが、これは望ましくない結合の形態だ。 _なぜ_ 望ましくないのかを正確に説明するのは難しいが、凝集性と結合性の観点から考えることができる。 `reOrderWidgets`メソッドは、`WidgetRepository`のインターフェースの凝集性を低下させ、システム内の概念の結合度を高める。ウィジェットのデータベースにアクセスしたいだけのクライアントが、再発注のロジックにも結合してしまう。 これでもよいかもしれない。しかし、そうではないかもしれない。私たちは、この変更案の実際の影響について議論する方法を持っている。そして、これでは良く _ない_ と仮定すると、インターフェースを分離するだけでは不十分だ。全く別のクラスを作りたいと思う。 ```java class WidgetReOrdering { private WidgetRepository widgetRepository; public WidgetReOrdering(WidgetRepository widgetRepository) { this.widgetRepository = widgetRepository; } public void reOrderWidgets() { for (Widget w: this.widgetRepository.find("quantity < 10")) { // call the fulfillment API } } } ``` 解決策はインターフェースと実装を分離することだったが、述べられているインターフェース分離原則が実際にどのように役立ったのかを理解するのは難しい。代わりに、凝集性と結合性について直接話し合うことで、問題のある設計を回避した。重要なのは、私たちが懸念していた結合は、コードではなく概念的なものだったということだ。もし`WidgetRepository`にウィジェットを削除するための新しいメソッドが必要だったとしたら、それはコードの結合度を高めたことになるが、概念の結合度は高めなかっただろう。 _これこそ_ が設計へのアプローチの仕方だ。どんな犠牲を払ってでも結合度を下げることが正しいやり方ではない。 私のアドバイス: **インターフェースを分離することは、結合度を下げ、凝集性を高めるための技術だが、極端に行うと凝集性を下げてしまうこともある。常にそうするべきではない。システムの凝集性と結合性のバランスを取ることに集中すべきだ。** さて、最後の原則である依存性逆転の原則に移ろう。 -
May 27, 2024 . 1 changed file with 64 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,64 @@ # Liskov置換原則は...設計原則ではない(SOLIDはソリッドではない) https://naildrivin5.com/blog/2019/11/18/liskov-substitution-principle-is-not-a-design-principle.html 2019年11月18日 [元の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) で述べたように、私はSOLID原則が...思われるほどソリッド(堅牢)ではないことに気づいている。最初の投稿では、単一責任原則に私が見る問題点を概説した。2番目の投稿では、オープン/クローズド原則は混乱を招き、ほとんどの合理的な解釈では悪いアドバイスを与えるため、無視することを推奨した。さて、Liskov置換原則について話そう。これは、結局のところ、設計のアドバイスではないのだ。 この原則は、「プログラム内のオブジェクトは、プログラムの正しさを変えることなく、そのサブタイプのインスタンスと置き換え可能であるべきだ」と述べている。これを理解するには、「プログラムの正しさ」が何を意味するのかを知る必要がある。 それを理解するには、この原則がどこで開発されたかを見るのが役立つ。そして実際、この原則の名前の由来となったBarbara Liskovによって開発されたり、命名されたりしたのではない。 LiskovとJeannette Wingは、 _サブタイプ_ をプログラムの正しさに関連付ける方法を定義しようとする [論文](http://reports-archive.adm.cs.cmu.edu/anon/1999/CMU-CS-99-156.ps) を _著した_ 。その論文の中で、彼女らは、オブジェクト _x_ の代わりにオブジェクト _y_ を使用したが、 _y_ に _x_ と同じプロパティがすべてない場合、 _y_ は _x_ のサブタイプではないと述べている。 では、この原則はどのようにして生まれたのだろうか。驚くことではないが、答えは良くも悪くもUncle Bob Martin [^1] だ。彼はLiskovの研究を参照した [論文](https://web.archive.org/web/20150905081111/http://www.objectmentor.com/resources/articles/lsp.pdf) の中で、この原則について説明している。 [^1]: Robert Martin、通称「Uncle Bob」は、オンライン上で私の個人的な価値観と一致しない発言をしているので、私は彼の仕事を詳しくフォローしておらず、彼を尊敬してもいない。それにもかかわらず、彼はソフトウェアとオブジェクト指向設計の世界で影響力を持っており、多くの開発者に教えられているため、彼のアイデアを批判することには価値がある。Uncle Bobのオンライン上での行動について詳しく知りたい場合は、Twitterで彼を見つけてほしい。 Martinの論文では、この原則が解決しようとしている問題について強い主張をしておらず、この原則の存在を正当化する複雑な例を示しているが、この原則を理解したり適用したりする方法については何の指示もない。 ただ混乱していて曖昧だと片付けたくなるが、「正しさ」の使用に固執していることがとても気になる。 ## そもそも「プログラムの正しさ」とは正確には何なのだろうか? Wikipediaでは、[プログラムの正しさを次のように定義している](https://en.wikipedia.org/wiki/Correctness_(computer_science)) 。 > アルゴリズムが仕様に関して正しいと言われるのは、そのアルゴリズムが仕様に関して正しいと言われるときである。機能的正しさとは、アルゴリズムの入力-出力動作(つまり、各入力に対して予想される出力を生成すること)を指す。 この定義は妥当に思えるが、しかしここでも再び仕様が定まっているいう要件に直面する。ほとんどのソフトウェアの開発においては、定まった仕様が存在することはまれであるだけでなく、アジャイルソフトウェア開発(皮肉にもMartinによって開発され、支持されている)では、仕様を定めることをしばしば避け、ユーザーのフィードバックを得ながらソフトウェアを反復することを好む。 そのため、仕様を必要とする正しさに基づいて、定まっていない仕様でどのように設計を評価すればよいのか悩んでしまう。 しかし、正しさの定義を見たときにわかるような定義であっても、奇妙な道に導かれてしまう。 多数のファイルの内容をソートしたいとしよう。ファイルのディレクトリがあり、そのすべての行をソートして単一のファイルに出力したいとする。ソートの詳細は渡されたオブジェクトに委ねたいので、中心となるルーチンは次のようになるかもしれない。 ```rb def sort_files(files_dir, destination_file, sorter) files_in_dir = readdir(files_dir) sorter.sort_contents(files_in_dir, destination_file) end ``` `sort_files` の呼び出し側は、 `sorter` に任意の実装を提供できる。そして、それらの実装がプログラムの正しさを変えない限り、Liskov置換原則に違反しないため、設計は良いと考えられる。 2つの可能なソートアルゴリズムを考えてみよう。1つ目は、 `MemQuicksort` と呼ぶことにする。これは、すべてのファイルの行をメモリに読み込み、クイックソートを行う。そして、ソートされた結果を `destination_file` に書き込む。これは、プログラムの要件を満たしているように思える。 次に、 `FileMergeSort` と呼ぶ別の実装があるとしよう。これは、基本的にディスク上のファイルをソートし、すべての行をメモリに読み込むことを避けるためにマージソートを使用する。より多くのディスク容量を必要とするが、それほど多くのメモリは必要としない。これも、プログラムの要件を満たしているように思える。どちらの実装も、同じ入力を与えれば、同じ出力を生成する。 それとも違うだろうか? これら2つの実装は、ソフトウェアの振る舞い方を根本的に変えてしまう。そしてそれは「出力」とみなされるのではないだろうか? ソースコードの制御外の状況(つまり、ディスクの容量、メモリの容量、ファイルのサイズ)によっては、プログラムがまったく動作しないかもしれない。あるいは、望ましいよりも遅く動作するかもしれない。あるいは、必要なメモリのために実行コストが高すぎるかもしれない。 ご覧のとおり、このプログラムへの入力は、ファイルのあるディレクトリ、宛先ファイル、使用するソートアルゴリズムだけではない。プログラムが実行されるコンピュータ、割り当てられたメモリ、ディスクのサイズなど、いくつかの暗黙の入力がある。 つまり、正しさの定義では、プログラムの実際の動作を含む、 _すべて_ の入力と _すべて_ の出力を説明する必要がある、ということだ。そうだろう? そうだとすれば、 _どの_ サブタイプであれ、これらのいくつかに何らかの影響を与えないことがどうしてありえようか? そもそもサブタイプを作成する理由は、動作を変更するためだ。 これは、使用している正しさの定義によっては、 _すべて_ のサブタイプがこの原則に違反することを示している。そして、単一責任原則について議論する際には、問題のコードではなく「責任」とは何かについて議論することが多いのと同じように、Liskov置換原則は、コードについて話すのではなく、「正しさ」についての議論に堕してしまうのではないかと思わずにはいられない。 ここでの私の見解は、サブタイプに焦点を当てることは、設計を分析するための正しいレンズではない、ということだ。それは、設計を改善する方法について何の明快さも提供しない。このレンズはどのレベルでも設計のアドバイスとは見なしがたい。 私のアドバイス: **これは設計の指針ではないので、無視して、サブタイプについて話すのをやめ、抱えている問題を解決するソフトウェアを構築することに集中するべきだ。** 次は、インターフェース分離原則だ。これは、求められていないときに柔軟なコードを作るためのもう1つの処方箋だ。 -
May 27, 2024 . 1 changed file with 125 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,125 @@ # オープン/クローズドの原則は混乱させるし、まあ、間違っている(SOLIDはソリッドではない) https://naildrivin5.com/blog/2019/11/14/open-closed-principle-is-confusing-and-well-wrong.html 2019年11月14日 [SOLID](https://en.wikipedia.org/wiki/SOLID) 原則は、当初考えられていたほど「solid(堅牢)」ではないことに気づきつつあるのである。[前回の投稿](https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html) では、単一責任原則の問題点を概説したが、今回は5つの原則の中で最も理解しづらいオープン/クローズドの原則について述べたいと思う。 この原則は、ソフトウェアは「拡張に対してオープンであり、修正に対してクローズドであるべき」というものである。この要約は非常にわかりづらく、深く掘り下げてみると悪いアドバイスばかりであった。この原則は完全に無視すべきだ。その理由を見ていこう。 ## オープン/クローズドの原則の意味するところ この原則は(SOLIDにおける理解では)、ロバート・マーチン [^1] がバートランド・メイヤーの著書『 [Object-Oriented Software Construction](https://en.wikipedia.org/wiki/Object-Oriented_Software_Construction) 』での記述を基に書いた論文で提唱されたものである。 [^1]: ロバート・マーチン(通称「アンクル・ボブ」)は、私の個人的な価値観と一致しないようなオンライン上の発言をしているので、私は彼の仕事を熱心にフォローしておらず、彼を高く評価してもいない。それでも、彼はソフトウェアやオブジェクト指向設計の世界で影響力を持っており、多くの開発者に教えられている彼のアイデアを批判することには価値がある。アンクル・ボブのオンライン上の行動について詳しく知りたい方は、Twitterで彼を探してみてほしい。 マーチンはメイヤーの言葉を次のようにパラフレーズしている。 > ソフトウェアの構成要素(クラス、モジュール、関数など)は、拡張に対してオープンであり、修正に対してクローズドであるべきだ。 そして、「拡張に対してオープン」とは、アプリケーションの要件が変更されたり、新しいアプリケーションのニーズに対応したりするために、モジュールを「新しく異なる方法で動作させることができる」ことを意味すると定義している。一方、「修正に対してクローズド」とは、「誰もそのソースコードを変更することを許されない」ことを意味すると定義している。 はあ?これは全く逆のように思えるのだが。 コードに不必要な柔軟性を追加すること(拡張に対してオープンにすること)は、複雑さとキャリングコストを生み出す。究極的な柔軟性を実現するために、存在しないありとあらゆるユースケースを想像する必要がある。これは時間の無駄であり、より複雑でわかりにくいコードを生み出し、必要のないすべての柔軟性を永続的にメンテナンスすることを要求するのである。 ソースコードを変更できないという考え方ほど奇妙ではないが、バグを修正するためにコードを変更できないとしたら、どうすればよいのだろうか。削除して最初からやり直すのか。この原則のこの部分は明らかに間違っているように思えて、自分の現実認識を疑ってしまう。 この論文を掘り下げてみると、クラスは抽象基底クラスに依存すべきであり、それによって特定のクラスの実装を、そのクラスの利用者に影響を与えることなく入れ替えることができるようにすべきだと述べているようである。そして、これが一つの _原則_ であるため、私の解釈では、常にこのようにすべきだということになる。 これは悪いアドバイスである。柔軟性はほとんど必要とされず、ほとんどの場合、解決するよりも多くの問題を生み出す。また、システムの振る舞いを理解するのが難しくなることもあり得る。 ## 柔軟性はコストがかかる 他の条件が同じであれば、より柔軟性の高いコードは、構築、テスト、メンテナンスがより難しくなる。必要のない機能をコードに組み込むことは余分な作業だ。キャリングコストの概念だけでも、クラスを「拡張に対してオープン」にするために必要な作業は避けるべきだ。柔軟性が必要ないのであれば、構築してはいけない。 そのキャリングコストの一つが、システムの振る舞いを理解する能力だ。高い柔軟性を持つコードは、ナビゲートすべきコードパスを多く生成し、この論文で示されているような柔軟性(抽象基底クラスを追加すること)は、それらのコードパスを発見するのを難しくする。 何について話しているのかを見てみよう。この論文では、`Server`に依存する`Client`の例が示されている。 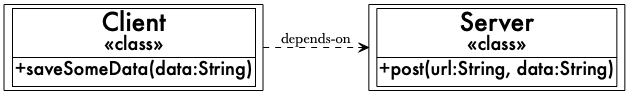 論文の `Client` と `Server` の関係の再現([新しいウィンドウでより大きなバージョンを表示](https://naildrivin5.com/images/open-closed-client-server.png)) そのコードはJavaでは次のようになる(Rubyには型アノテーションがないため、これを見るのは難しい)。 ```java public class Client { private Server server; public Client() { this.server = new Server(); } public void saveSomeData(String data) { this.server.post("/foo", data); } } public class Server { public void post(String url, String data) { // .... } } ``` オープン/クローズドの原則によると、このクラスは、常に具象の`Server`インスタンスを使用するため、拡張に対してオープンではなく、また、別のタイプのサーバーに変更したい場合は、ソースコードを変更しなければならないため、修正に対してクローズドでもない。 これらの変更を行う _必要がある_ というのは、既定路線の結論ではない。また、実際に柔軟性が必要な場合、このクラスがその柔軟性を追加しなければならない場所であるかどうかも明らかではない。 それでも、この論文(つまり原則)では、この問題に対処する方法をこのように述べている。すなわち、サーバーの実装のための抽象基底クラスを導入し、`Client`にはその基底クラスに依存させるべきだと。 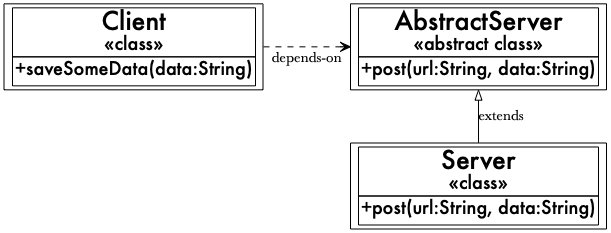 論文の`Client`、`AbstractServer`、`Server`の関係の再現([新しいウィンドウでより大きなバージョンを表示](https://naildrivin5.com/images/open-closed-client-abstract-server.png)) Javaでは、次のようになる。 ```java public abstract class AbstractServer { abstract void post(String url, String data); } public class Server extends AbstractServer { public void post(String url, String data) { // .... } } public class Client { public Client(AbstractServer server) { this.server = server; } } ``` そして、`Client`インスタンスを作成するときは、常に具象の実装を渡す。 ```java Client client = new Client(new Server()) ``` `Client`は、`AbstractServer`の別の実装を渡すことができるため、拡張に対してオープンになり、そのためにソースを変更する必要がないため、修正に対してクローズドになった。 これはより柔軟な設計だが、果たしてより良いものだろうか。私は、これが _絶対的に_ より良いものだとは思えない。複数の`Server`が必要ない場合、コードに不要な機能を追加してしまい、それを維持しなければならなくなる。この例では些細なことに思えるかもしれないが、このようにして構築された全体のコードベースを想像してみてほしい。私はそのようなコードベースで作業したことがあるが、楽しいものではなかった。そのためのコードを書くには、必要のない抽象基底クラス(またはインターフェース)を作るという余分な手順が必要だった。 しかし、そのことはシステムの振る舞いを説明し、予測することを _本当に_ 難しくしてしまった。 ## システムの振る舞いを理解することが最も重要 プログラマーとして、システムの実際の振る舞いを _頻繁に_ 説明し、理解しなければならない。バグを診断して修正したり、システムで何が起こったのかを他の人に説明したり、機能を追加するために変更を加えたりしなければならないのだ。 オープン/クローズドの原則に違反している最初の実装では、柔軟性がないため、システムの振る舞いを説明するのは非常に簡単だ。`Client`は常に`Server`を使用するため、コードを通るパスは明確である。 しかし、2番目の実装では、より難しくなる。`Server`が`AbstractServer`の唯一の実装かどうかわからないと仮定すると、システムの観測された振る舞いを理解するためには、`Client`のすべての使用箇所を追跡して、どの`AbstractServer`の実装が使用されたかを把握し、どのパスがどれを使用したかを把握しなければならない。 `AbstractServer` の実装が1つしかないことを発見するためにそれを行うことを想像してみてほしい。 システムが必要とする以上に柔軟になるようにクラスを設計すると、複雑さが生まれる。プログラマーが必要になるかもしれないと考えている柔軟性を追加する場合、今の時点で柔軟性を追加することで後で時間を節約しようというアイデアがある。しかし、どのような柔軟性が必要なのかは、常にはわからないのだ。システムを _本当に_ 柔軟にするためには、必要なことだけを実装し、十分にテストされていなければならない。 私のアドバイスは次のとおりだ。**オープン/クローズドの原則は完全に無視すること。目の前の問題を解決するためのコードを書くこと。** 残りのSOLID原則を見ていくと、必要のない場合にも柔軟性を追加するという繰り返しのテーマが見えてくるだろう。それは一体何のためなのか...よくわからない。 次はリスコフの置換原則だ。 -
May 27, 2024 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -123,7 +123,7 @@ end ウィジェットの作成とそれに関するEメールの送信は、一緒にあるべきもののように思えるので、この変更はこのクラスのまとまりに実質的な影響を与えないと主張したい[^2]. [^2]: また、この変更がリファクタリング後のバージョンでどのように物事を複雑にしていたかにも注目すべきだ。このコードを `WidgetRouter` に追加する必要があり、それは非常に間違っていると感じられるはずであり、したがって、この1行のコードを追加するためには、より大規模なリファクタリングが必要になるのだ。 ウィジェットを保持するテーブルのデータベース統計を記録する、別の変更を見てみよう: -
May 27, 2024 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -99,7 +99,7 @@ _凝集性_ とは、コンピュータ・サイエンスで長い間議論さ 凝集性だって単一責任原則と同様に曖昧だが、 _原則_ としては提示されておらず、遵守しなければならない客観的な尺度としても提示されていない。 強力な規定措置がないということは、責任の数を数えるのをやめて、今あるコードとそれに加えたい変更について話し始めることができるということだ。 元のコントローラに対する2つの変更を見てみよう。これらの変更はどちらも単一責任の原則に違反することになる。しかし、クラスの凝集性に重大な影響を与えるのは1つだけだ。 最初の例では、ウィジェットが作成されるたびにメールを送信するコードを追加する。 -
May 27, 2024 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -97,7 +97,7 @@ end _凝集性_ とは、コンピュータ・サイエンスで長い間議論されてきた概念で、要素(コードの一部)が一緒になっているモジュール(コードのグループ化を意味する)は、要素が一緒になっていないモジュールよりも保守性が高く、理解しやすいというものだ。 凝集性だって単一責任原則と同様に曖昧だが、 _原則_ としては提示されておらず、遵守しなければならない客観的な尺度としても提示されていない。 強力な規定措置がないということは、責任を数えるのをやめて、今あるコードとそれに加えたい変更について話し始めることができるということだ。 元のコントローラに対する2つの変更を見てみよう。これらの変更はどちらも単一責任の原則に違反することになる。しかし、クラスの凝集性に重大な影響を与えるのは1つだけだ。 -
May 27, 2024 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -58,7 +58,7 @@ end 「バグフィックスと新機能」という変更理由はさておき、このクラスには変更する理由がたくさんありそうだ。 ウィジェットを要求するために必要なパラメータを追加するかもしれない。 ウィジェットが作成されたときに、ユーザを別の場所にルーティングする必要があると判断するかもしれない。 ウィジェットが作成されるたびに、管理者にメールを送信する必要があるかもしれない。つまり、このコードが単一責任原則に違反していることは明らかであり、したがって悪いことであり、変更されるべきなのだ。そうだろう? ここでそれを受け入れるのは難しい。 このコードは、Railsが推奨するコードの書き方の規範になっているだけでなく、短く、直接的で、要点がまとまっている。 もちろん、時間が経てばこのコントローラにさらにコードを追加することもできるし、コントローラが大きく複雑になることもあるだろう。しかし、このコードの変更理由が _正確に1つ_ であるべきだとか、修正が必要だと言うのだろうか?それは意味がない。 科学のために、このコードを変更して責任の数を減らしてみよう。 -
May 27, 2024 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -58,7 +58,7 @@ end 「バグフィックスと新機能」という変更理由はさておき、このクラスには変更する理由がたくさんありそうだ。 ウィジェットを要求するために必要なパラメータを追加するかもしれない。 ウィジェットが作成されたときに、ユーザを別の場所にルーティングする必要があると判断するかもしれない。 ウィジェットが作成されるたびに、管理者にメールを送信する必要があるかもしれない。つまり、このコードが単一責任原則に違反していることは明らかであり、したがって悪いことであり、変更されるべきなのだ。そうだろう? ここでそれを受け入れるのは難しい。 このコードは、Railsが推奨するコードの書き方の規範になっているだけでなく、短く、直接的で、要点がまとまっている。 もちろん、時間が経てばこのコントローラにさらにコードを追加することもできるし、コントローラが大きく複雑になることもあるだろう。しかし、このコードの変更理由が _正確に1つ_ であるべきだとか、変更が必要だと言うのだろうか?それは意味がない。 科学のために、このコードを変更して責任の数を減らしてみよう。 -
May 27, 2024 . 1 changed file with 2 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,6 +1,8 @@ # SOLIDはソリッドではない - 単一責任原則を検証する https://naildrivin5.com/blog/2019/11/11/solid-is-not-solid-rexamining-the-single-responsibility-principle.html 2019年11月11日 最近、SOLIDの原則について考えていて、その有用性に疑問を感じている。 SOLIDの原則は曖昧で、範囲が広すぎて、混乱を招き、場合によっては完全に間違っている。しかし、これらの原則の動機は正しい。問題は、ニュアンスの異なる概念を簡潔な文に落とし込もうとすることにあって、翻訳の過程で価値の大部分を失っているのだ。 これはプログラマーを間違った道へと導いてしまう(私にとっては確かにそうだった)。 -
May 27, 2024 .There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,152 @@ # SOLIDはソリッドではない - 単一責任原則を検証する 2019年11月11日 最近、SOLIDの原則について考えていて、その有用性に疑問を感じている。 SOLIDの原則は曖昧で、範囲が広すぎて、混乱を招き、場合によっては完全に間違っている。しかし、これらの原則の動機は正しい。問題は、ニュアンスの異なる概念を簡潔な文に落とし込もうとすることにあって、翻訳の過程で価値の大部分を失っているのだ。 これはプログラマーを間違った道へと導いてしまう(私にとっては確かにそうだった)。 おさらいとして、[SOLID](https://en.wikipedia.org/wiki/SOLID)の原則は以下の通りである: - 単一責任原則 - オープン/クローズの原則 - リスコフの置換原理 - インターフェース分離の原則 - 依存関係の逆転原理 今回は「単一責任原則」を取り上げ、4回にわたって他の原則に取り組む。 ## 単一責任原則 [ウィキペディアには](https://en.wikipedia.org/wiki/Single_responsibility_principle) 次のように書かれている。 > つまり、ソフトウェアの仕様のひとつに対する変更だけが、そのクラスの仕様に影響を与えることができる。 これはかなり曖昧だ。「仕様」とは何だろう? 私はこの23年間、仕様の定まったソフトウェアに携わったことがない。 そして、ここでの「影響」とは何を意味するのか? ウィキペディアの記事では、「例」のセクションで説明している(強調は原文のまま): > マーティン[この言葉を作ったロバート・マーティン [^1] ]は、責任とは変更理由であると定義している。 [^1]: ロバート・マーティン、別名 "アンクル・ボブ "は、私の個人的価値観と矛盾する発言をオンライン上で行っている。 とはいえ、彼はソフトウェアとオブジェクト指向設計の世界で影響力を持っており、彼のアイデアは多くの開発者によって教えられているため、彼の考えを批判することには価値があるのだ。アンクル・ボブのオンライン上での行動についてもっと知りたいのであれば、Twitterで彼を見つけるのがよいだろう。 というのも、 _すべて_ のコードには、バグを修正するか機能を追加するかという、少なくとも _2つ_ の変更理由があるからだ。では、それらが別の理由と見なされないのであれば、「理由」とは何なのか? そこが曖昧なので、コードレビューに単一責任原則を適用するとだいたい泥沼化する。というのも、誰もがレビュー中のコードの質ではなく、原則をどう解釈するかについて話し始めるからだ。 とはいえ、コードが持つべき仕事/事柄/責任は1つだけというのは正しい _気がする_ 。 このRailsコントローラを考えてみよう: ```rb class WidgetsController < ApplicationController def create @widget = Widget.create(widget_params) if @widget.valid? redirect_to :index else render :new end end def widget_params params.require(:widget).permit(:name, :price) end end ``` これは非常にバニラな実装で、新しいウィジェットが有効であればデータベースに保存し、有効でなければ、バリデーションの問題を修正するためにユーザーをフォームに送り返す。 「バグフィックスと新機能」という変更理由はさておき、このクラスには変更する理由がたくさんありそうだ。 ウィジェットを要求するために必要なパラメータを追加するかもしれない。 ウィジェットが作成されたときに、ユーザを別の場所にルーティングする必要があると判断するかもしれない。 ウィジェットが作成されるたびに、管理者にメールを送信する必要があるかもしれない。つまり、このコードが単一責任原則に違反していることは明らかであり、したがって悪いことであり、変更されるべきなのだ。そうだろう? ここでそれを受け入れるのは難しい。 このコードは、Railsが推奨するコードの書き方の規範になっているだけでなく、短く、直接的で、要点がまとまっている。 もちろん、時間が経てばこのコントローラにさらにコードを追加することもできるし、コントローラが大きく複雑になることもあるだろう。しかし、このコードが _正確に1つ_ であるべきだとか、変更が必要だと言うのだろうか?それは意味がない。 科学のために、このコードを変更して責任の数を減らしてみよう。 ```rb class WidgetsController < ApplicationController def create @widget = WidgetCreator.create(params) WidgetRouter.route(self, @widget) end end class WidgetCreator def self.create(params) Widget.create(params.require(:widget).permit(:name, :price) end end class WidgetRouter def self.route(controller, widget) if widget.valid? controller.redirect_to :index else controller.render :new end end end ``` 各クラスの責任は確かに軽くなり、変わる理由も少なくなった。しかし、これを改善と見るのは難しい。確かに、ウィジェットの作成方法が複雑になれば、別のクラスを持つことに価値があるかもしれない。また、作成時のルーティングが多くの微妙なルールに左右されるのであれば、それを抽出することに価値があるかもしれないが、今回はそうではない。決してこのコードが優れているわけではない。 このことが私に教えてくれるのは、単一責任原則はそのままでは役に立たず、盲目的に固執すれば、解決しようとしている以上の問題を引き起こすかもしれないということだ。 とはいえ、単一責任原則の意図は正しい。それは、モジュールの要素がどの程度まとまっているかという [凝集性](https://en.wikipedia.org/wiki/Cohesion_(computer_science)) についての方向性を与えようとしているのである。 問題は、結束はそれほど単純明快ではないということだ。 ## 凝集性 _凝集性_ とは、コンピュータ・サイエンスで長い間議論されてきた概念で、要素(コードの一部)が一緒になっているモジュール(コードのグループ化を意味する)は、要素が一緒になっていないモジュールよりも保守性が高く、理解しやすいというものだ。 単一責任原則のように、凝集性は曖昧だが、 _原則_ としては提示されておらず、遵守しなければならない客観的な尺度としても提示されていない。 強力な規定措置がないということは、責任を数えるのをやめて、今あるコードとそれに加えたい変更について話し始めることができるということだ。 元のコントローラに対する2つの変更を見てみよう。これらの変更はどちらも単一責任の原則に違反することになる。しかし、クラスの凝集性に重大な影響を与えるのは1つだけだ。 最初の例では、ウィジェットが作成されるたびにメールを送信するコードを追加する。 ```rb class WidgetsController < ApplicationController def create @widget = Widget.create(widget_params) if @widget.valid? WidgetMailer.widget_created(@widget) # <------ redirect_to :index else render :new end end def widget_params params.require(:widget).permit(:name, :price) end end ``` ウィジェットの作成とそれに関するEメールの送信は、一緒にあるべきもののように思えるので、この変更はこのクラスのまとまりに実質的な影響を与えないと主張したい[^2]. [^2]: また、この変更がリファクタリングされたバージョンでどのように物事を複雑にしていたかに注目してほしい。 このコードをWidgetRouterに追加しなければならないが、これは非常に間違っていると感じられるはずで、この1行のコードを追加するために、より大きなリファクタリングが必要になる。 ウィジェットを保持するテーブルのデータベース統計を記録する、別の変更を見てみよう: ```rb class WidgetsController < ApplicationController def create @widget = Widget.create(widget_params) if @widget.valid? DatabaseStatistics.object_created(:widget) # <----- redirect_to :index else render :new end end def widget_params params.require(:widget).permit(:name, :price) end end ``` コントローラーはデータベースとは何の関係もない。だから、この変更は、私たちがこの変更に疑問を持つのに十分なほど、クラスのまとまりを弱めるように感じる。 しかし、どちらの場合も単一責任原則に違反している。 このことは、凝集性の概念を単一責任原則に当てはめることが絶対に間違っていることを物語っている。 私からのアドバイスだ: **単一責任について話すのをやめて、凝集性の話を始めよう。** 次回は「オープン/クローズの原則」を取り上げる。この原則は、全く役に立たないほど混乱している。