Last active
December 1, 2019 09:53
-
-
Save saptak/2d062b535ed9695af9e9 to your computer and use it in GitHub Desktop.
Revisions
-
saptak revised this gist
Sep 2, 2015 . 1 changed file with 9 additions and 10 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -250,15 +250,15 @@ Is the base class, where the topology configurations is initialized from the /re This is the storm topology configuration class, where the Kafka spout and LogTruckevent Bolts are initialized. In the following method the Kafka spout is configured. ```java private SpoutConfig constructKafkaSpoutConf() { … SpoutConfig spoutConfig = new SpoutConfig(hosts, topic, zkRoot, consumerGroupId); … spoutConfig.scheme = new SchemeAsMultiScheme(new TruckScheme()); return spoutConfig; } ``` A logging bolt that prints the message from the Kafka spout was created for debugging purpose just for this tutorial. @@ -347,4 +347,3 @@ public void execute(Tuple tuple) ###Summary In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence. -
Sep 2, 2015 . 1 changed file with 50 additions and 49 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -214,7 +214,7 @@ Go back to the Storm UI and click on “truck-event-processor” topology to dri You can press `Ctrl-C` to stop the Kafka producer ** Under Storm User view: ** You should be able to see the topology created by you under storm user views. 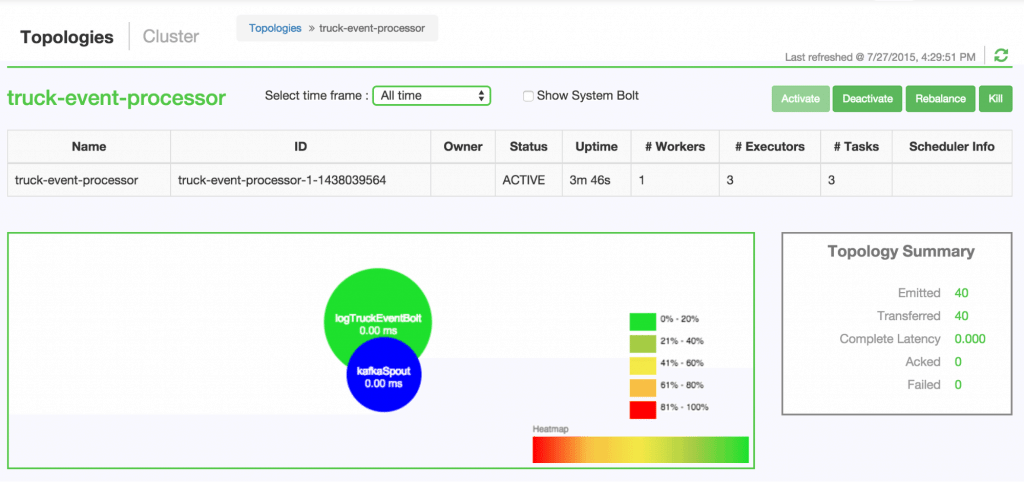 @@ -264,86 +264,87 @@ This is the storm topology configuration class, where the Kafka spout and LogTru A logging bolt that prints the message from the Kafka spout was created for debugging purpose just for this tutorial. ```java public void configureLogTruckEventBolt(TopologyBuilder builder) { LogTruckEventsBolt logBolt = new LogTruckEventsBolt(); builder.setBolt(LOG_TRUCK_BOLT_ID, logBolt).globalGrouping(KAFKA_SPOUT_ID); } ``` The topology is built and submitted in the following method; ```java private void buildAndSubmit() throws Exception { ... StormSubmitter.submitTopology("truck-event-processor", conf, builder.createTopology()); } ``` * **TruckScheme.java** Is the deserializer provided to the kafka spout to deserialize kafka byte message stream to Values objects. ```java public List<Object> deserialize(byte[] bytes) { try { String truckEvent = new String(bytes, "UTF-8"); String[] pieces = truckEvent.split("\\|"); Timestamp eventTime = Timestamp.valueOf(pieces[0]); String truckId = pieces[1]; String driverId = pieces[2]; String eventType = pieces[3]; String longitude= pieces[4]; String latitude = pieces[5]; return new Values(cleanup(driverId), cleanup(truckId), eventTime, cleanup(eventType), cleanup(longitude), cleanup(latitude)); } catch (UnsupportedEncodingException e) { LOG.error(e); throw new RuntimeException(e); } } ``` * **LogTruckEventsBolt.java** LogTruckEvent spout logs the kafka message received from the kafka spout to the log files under `/var/log/storm/worker-*.log` ```java public void execute(Tuple tuple) { LOG.info(tuple.getStringByField(TruckScheme.FIELD_DRIVER_ID) + "," + tuple.getStringByField(TruckScheme.FIELD_TRUCK_ID) + "," + tuple.getValueByField(TruckScheme.FIELD_EVENT_TIME) + "," + tuple.getStringByField(TruckScheme.FIELD_EVENT_TYPE) + "," + tuple.getStringByField(TruckScheme.FIELD_LATITUDE) + "," + tuple.getStringByField(TruckScheme.FIELD_LONGITUDE)); } ``` ###Summary In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence. -
Sep 2, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -17,7 +17,7 @@ In an event processing pipeline, each stage is a purpose-built step that perform In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored collecting and transporting data using Apache Kafka. So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed before the next steps of this tutorial. ### Scenario -
Sep 2, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -6,7 +6,7 @@ In this tutorial, we will explore [Apache Storm](http://hortonworks.com/hadoop/s 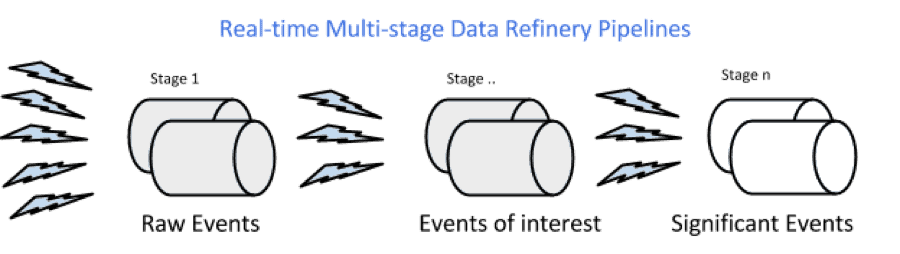 In an event processing pipeline, each stage is a purpose-built step that performs some real-time processing against upstream event streams for downstream analysis. This produces increasingly richer event streams, as data flows through the pipeline: * _raw events_ stream from many sources, * those are processed to create _events of interest_, and -
Sep 2, 2015 . 1 changed file with 9 additions and 9 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -4,6 +4,15 @@ In this tutorial, we will explore [Apache Storm](http://hortonworks.com/hadoop/storm) and use it with [Apache Kafka](http://hortonworks.com/hadoop/kafka) to develop a multi-stage event processing pipeline.  In an event processing pipeline, we can view each stage as a purpose-built step that performs some real-time processing against upstream event streams for downstream analysis. This produces increasingly richer event streams, as data flows through the pipeline: * _raw events_ stream from many sources, * those are processed to create _events of interest_, and * events of interest are analyzed to detect _significant events_. ### Prerequisite In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored collecting and transporting data using Apache Kafka. @@ -76,15 +85,6 @@ Each node in a Storm topology executes in parallel. In your topology, you can sp A topology runs indefinitely until you terminate it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. ###Steps -
Sep 1, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -344,6 +344,6 @@ LogTruckEvent spout logs the kafka message received from the kafka spout to the } ``` ###Summary In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence. -
Sep 1, 2015 . No changes.There are no files selected for viewing
-
Sep 1, 2015 . 1 changed file with 2 additions and 2 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -142,7 +142,7 @@ Now you can see the UI: 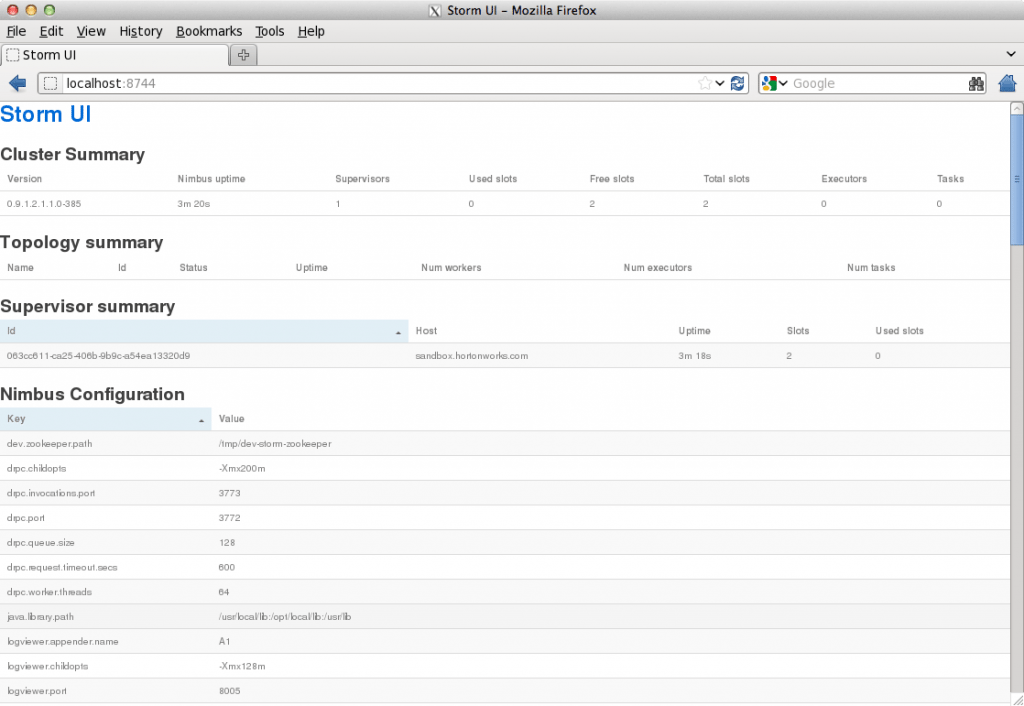 4. **Storm User View: **You can alternatively use Storm User View as well to view the topologies created by you. * Go to the Ambari User VIew icon and select Storm : @@ -212,7 +212,7 @@ Go back to the Storm UI and click on “truck-event-processor” topology to dri  You can press `Ctrl-C` to stop the Kafka producer **Under Storm User view: ** You should be able to see the topology created by you under storm user views. -
Sep 1, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -8,7 +8,7 @@ In this tutorial, we will explore [Apache Storm](http://hortonworks.com/hadoop/s In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored collecting and transporting data using Apache Kafka. So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed before proceeding on to this tutorial. ### Scenario -
Sep 1, 2015 . 1 changed file with 4 additions and 12 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -52,16 +52,6 @@ Five key abstractions help to understand how Storm processes data: Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed onto to other bolts or stored in Hadoop. #### Streams The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics. @@ -72,9 +62,11 @@ A spout is a source of streams. For example, a spout may read tuples off of a Ka A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts. Bolts can do anything from running functions, filtering tuples, do streaming aggregations, do streaming joins, talk to databases, and more. #### Storm Topologies A Storm cluster is similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs,” on Storm you run “topologies.” “Jobs” and “topologies” are different in that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you terminate it). Networks of spouts and bolts are packaged into a “topology,” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream. Links between nodes in your topology indicate how tuples should be passed around. For example, if there is a link between Spout A and Bolt B, a link from Spout A to Bolt C, and a link from Bolt B to Bolt C, then every time Spout A emits a tuple, it will send the tuple to both Bolt B and Bolt C. All of Bolt B’s output tuples will go to Bolt C as well. -
Sep 1, 2015 . 1 changed file with 2 additions and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -247,7 +247,8 @@ Let us review the code used in this tutorial. The source files are under the `/o * **BaseTruckEventTopology.java** ```java topologyConfig.load(ClassLoader.getSystemResourceAsStream(configFileLocation)); ``` Is the base class, where the topology configurations is initialized from the /resource/truck_event_topology.properties files. -
Sep 1, 2015 . 1 changed file with 101 additions and 163 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -80,18 +80,9 @@ Links between nodes in your topology indicate how tuples should be passed around Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution.  A topology runs indefinitely until you terminate it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. #### Event Processing Pipeline @@ -103,202 +94,169 @@ In an event processing pipeline, we can view each stage as a purpose-built step * those are processed to create _events of interest_, and * events of interest are analyzed to detect _significant events_. ###Steps ####Step 1: Start and Configure Storm 1. View the Storm Services page Started by logging into Ambari as admin/admin. From the Dashboard page of Ambari, click on Storm from the list of installed services. (If you do not see Storm listed under Services, please follow click on Action->Add Service and select Storm and deploy it.)  2. Start Storm From the Storm page, click on Service Actions -> Start 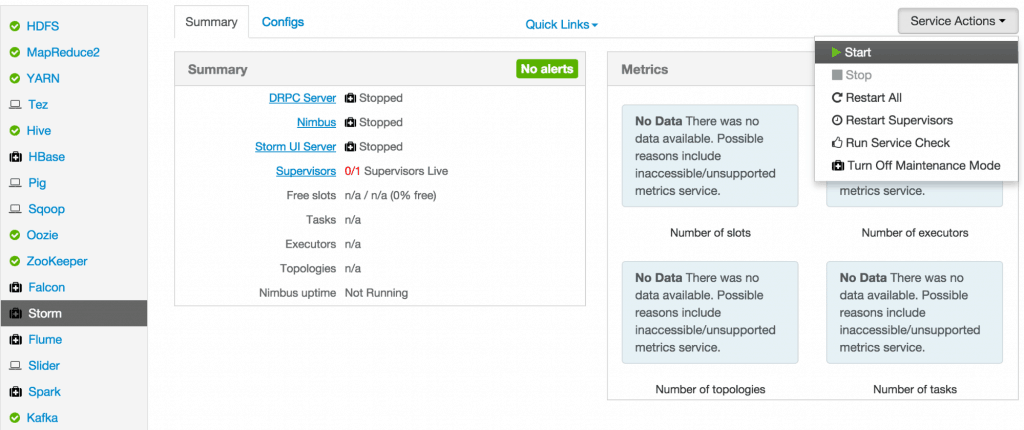 Check the box and click on Confirm Start: 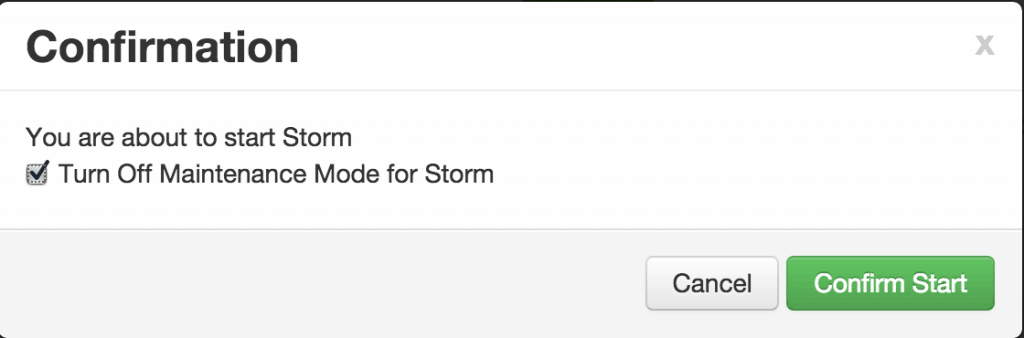 Wait for Storm to start. 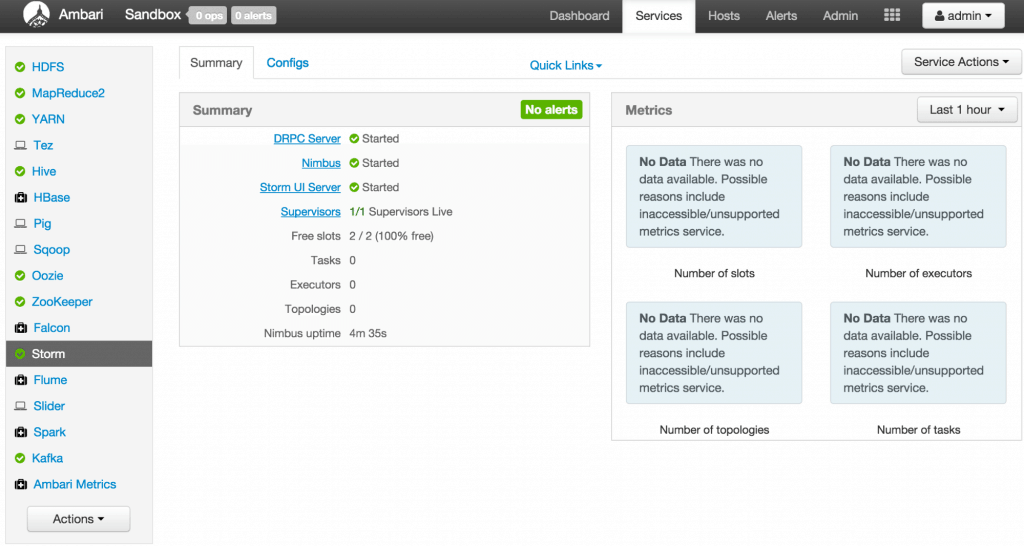 3. Configure Storm You can check the below configurations by pasting them into the Filter text box under the Service Actions dropdown * Check zookeeper configuration: ensure `storm.zookeeper.servers` is set to **sandbox.hortonworks.com** 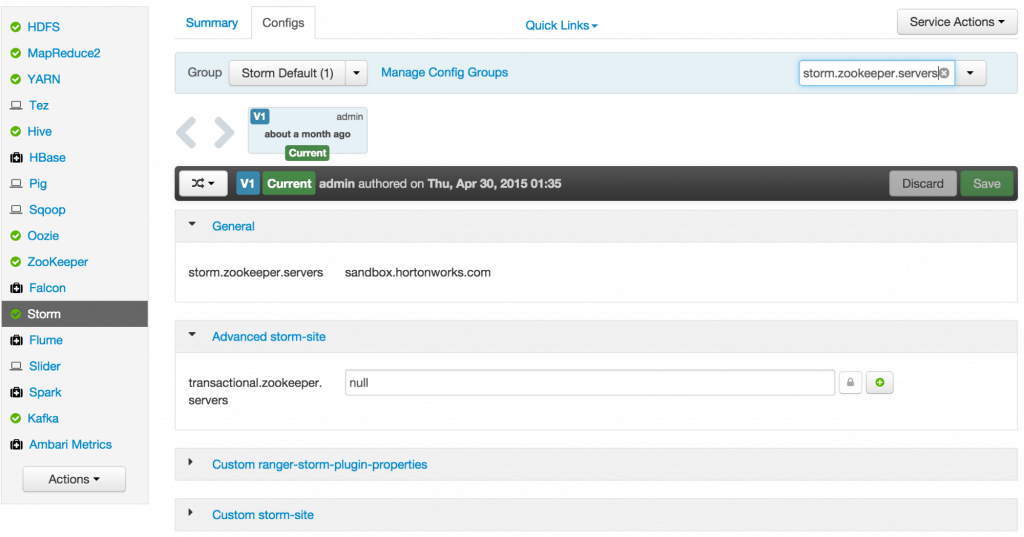 * Check the local directory configuration: ensure `storm.local.dir` is set to **/hadoop/storm** 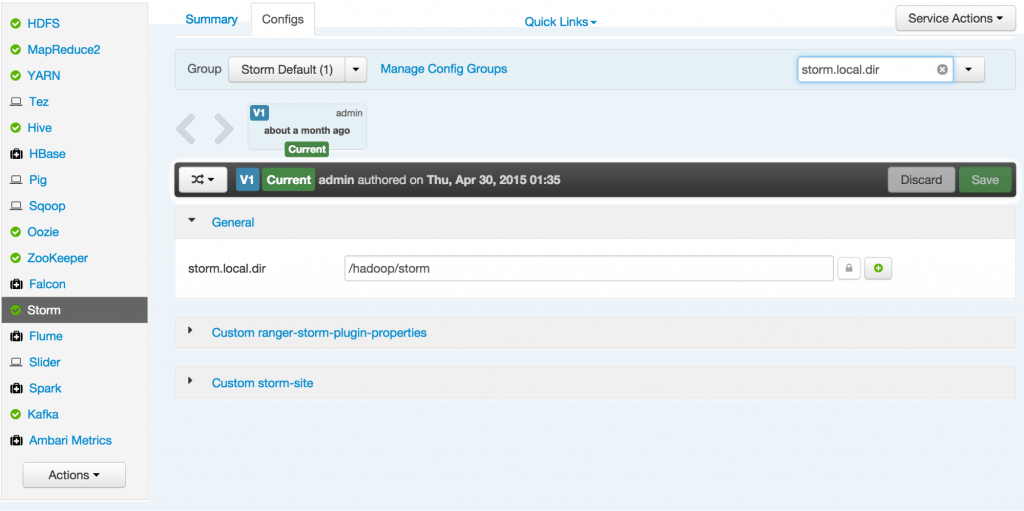 * Check the nimbus host configuration: ensure nimbus.host is set to sandbox.hortonworks.com 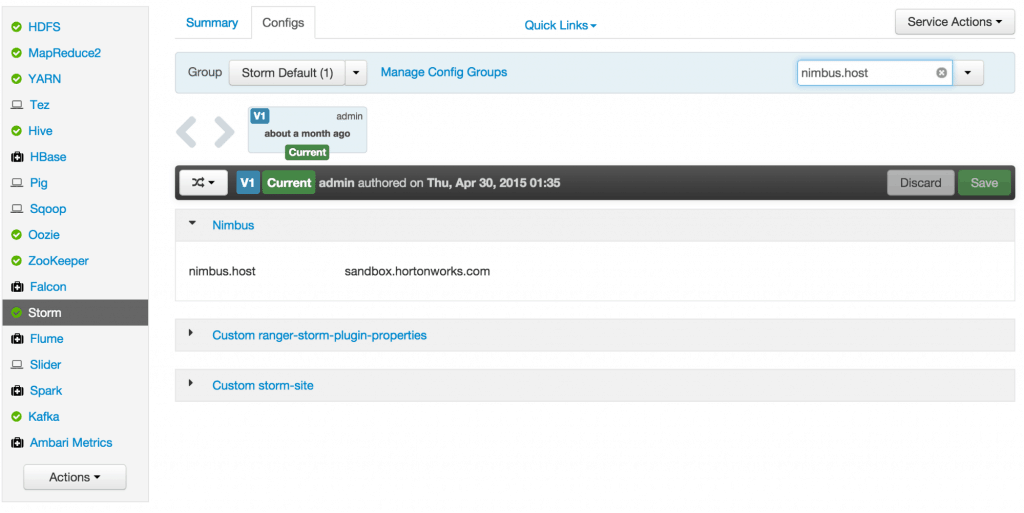 * Check the slots allocated: ensure supervisor.slots.ports is set to [6700, 6701] 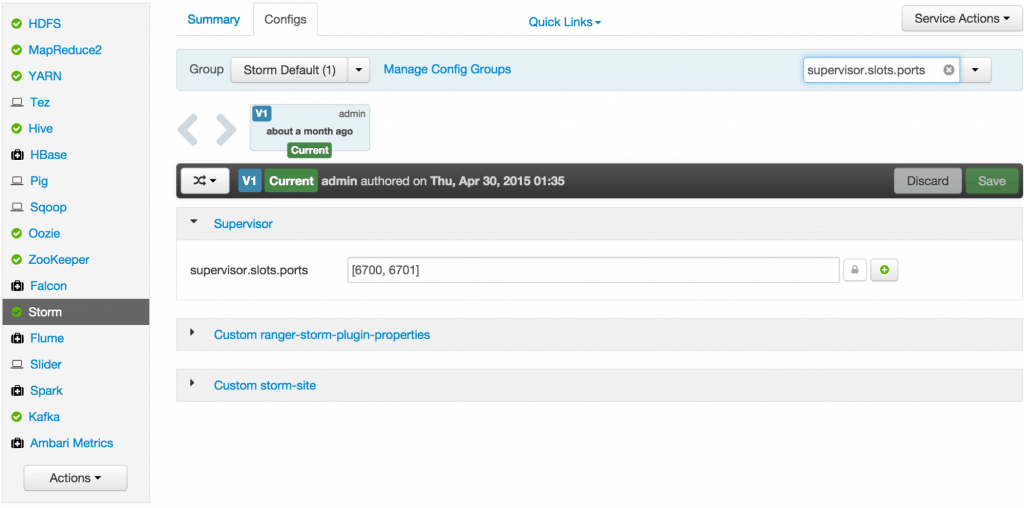 * Check the UI configuration port: Ensure ui.port is set to 8744 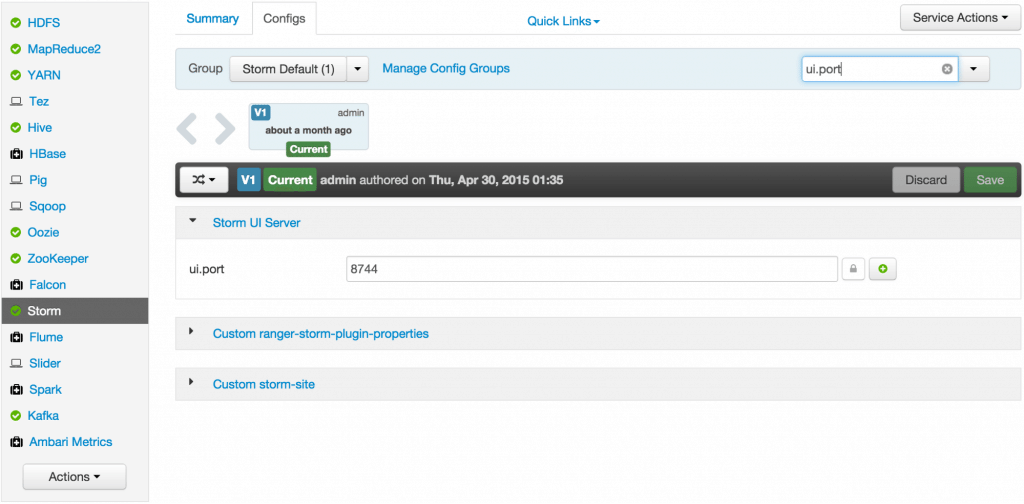 * Check the Storm UI from the Quick Links 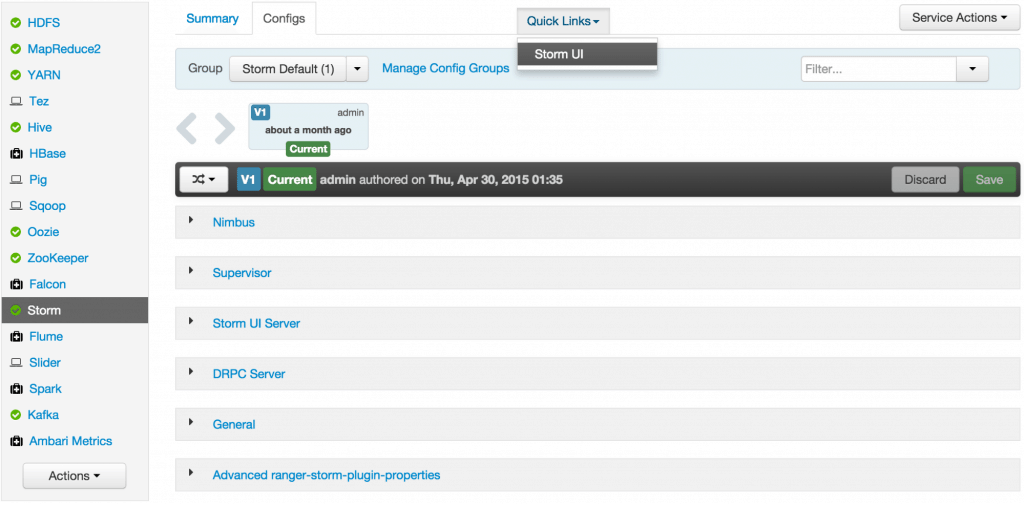 Now you can see the UI:  4. **Storm User View: **You can alternatively use Storm User View as well to view the topologies created by you. * Go to the Ambari User VIew icon and select Storm : 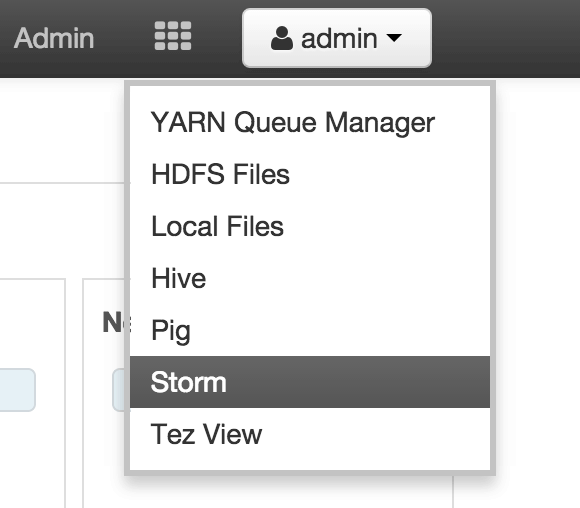 * The Storm user view gives you the summary of topologies created by you. As of now we do not have any topologies created hence none are listed in the summary.  #### Step 2. Creating a Storm Spout to consume the Kafka truck events generated in Tutorial #1 * **Load data if required:** From tutorial #1 you already have the required [New York City truck routes](http://www.nyc.gov/html/dot/downloads/misc/all_truck_routes_nyc.kml) KML. If required, you can download the latest copy of the file with the following command. ```bash wget http://www.nyc.gov/html/dot/downloads/misc/all_truck_routes_nyc.kml --directory-prefix=/opt/TruckEvents/Tutorials-master/src/main/resources/ ``` Recall that the source code is under `/opt/TruckEvents/Tutorials-master/src` directory directory and pre-compiled jars are under the `/opt/TruckEvents/Tutorials-master/target` directory * **Verify that Kafka process is running** Verify that Kafka is running using Ambari dashboard. If not, following the steps in tutorial #1 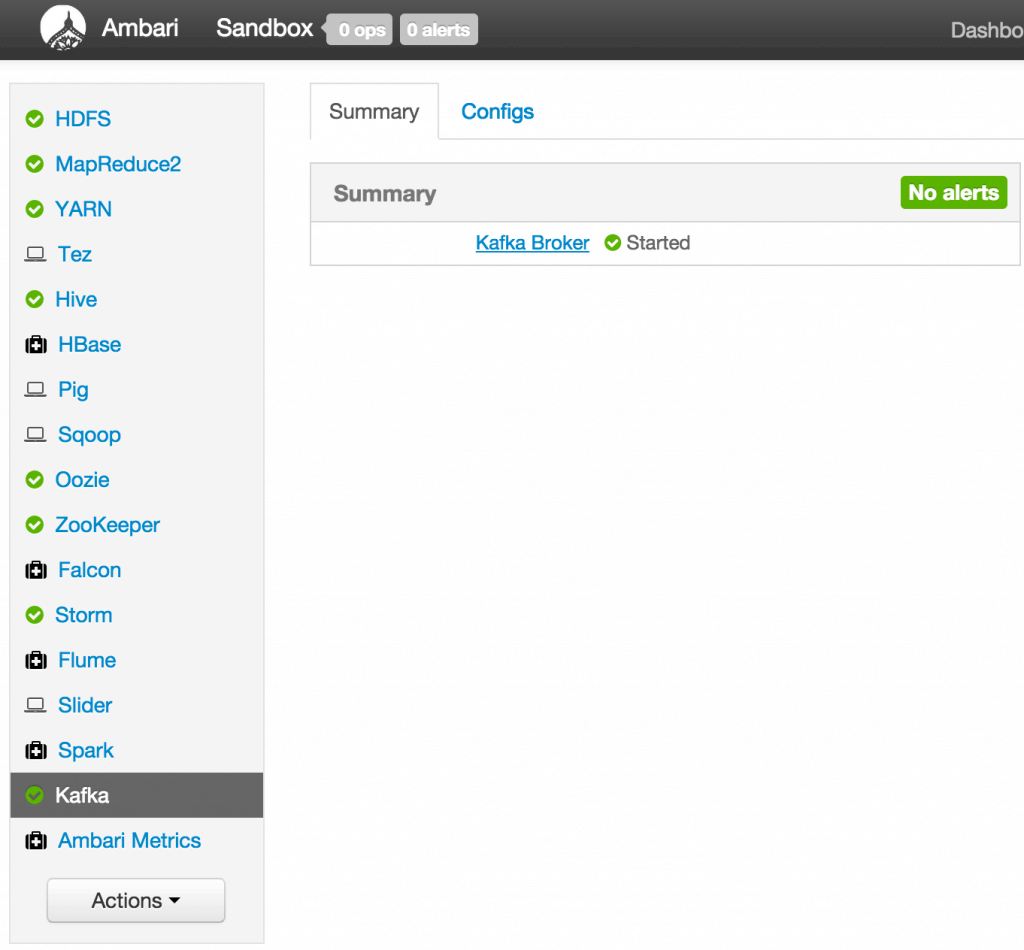 * **Creating Storm Topology** We now have ‘supervisor’ daemon and Kafka processes running. Running a topology is straightforward. First, you package all your code and dependencies into a single jar. Then, you run a command like the following: The command below will start a new Storm Topology for TruckEvents. ```bash cd /opt/TruckEvents/Tutorials-master/ storm jar target/Tutorial-1.0-SNAPSHOT.jar.com.hortonworks.tutorials.tutorial2.TruckEventProcessingTopology ``` 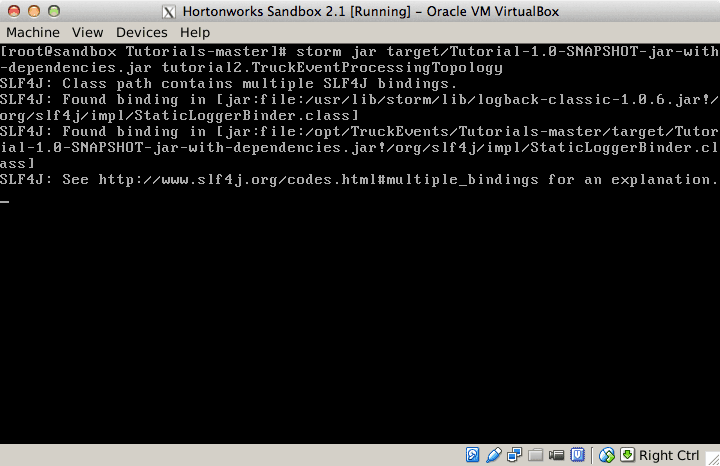 It should complete with “Finished submitting topology” as shown below. 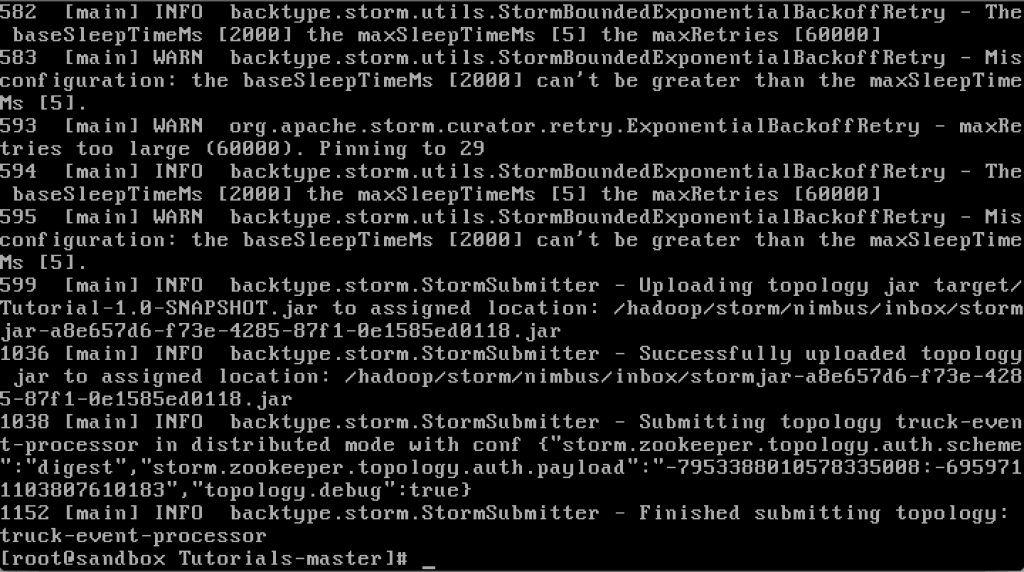 This runs the class TruckEventProcessingTopology . The main function of the class defines the topology and submits it to Nimbus. The storm jar part takes care of connecting to Nimbus and uploading the jar. Refresh the Storm UI browser window to see new Topology ‘truck-event-processor’ in the browser. 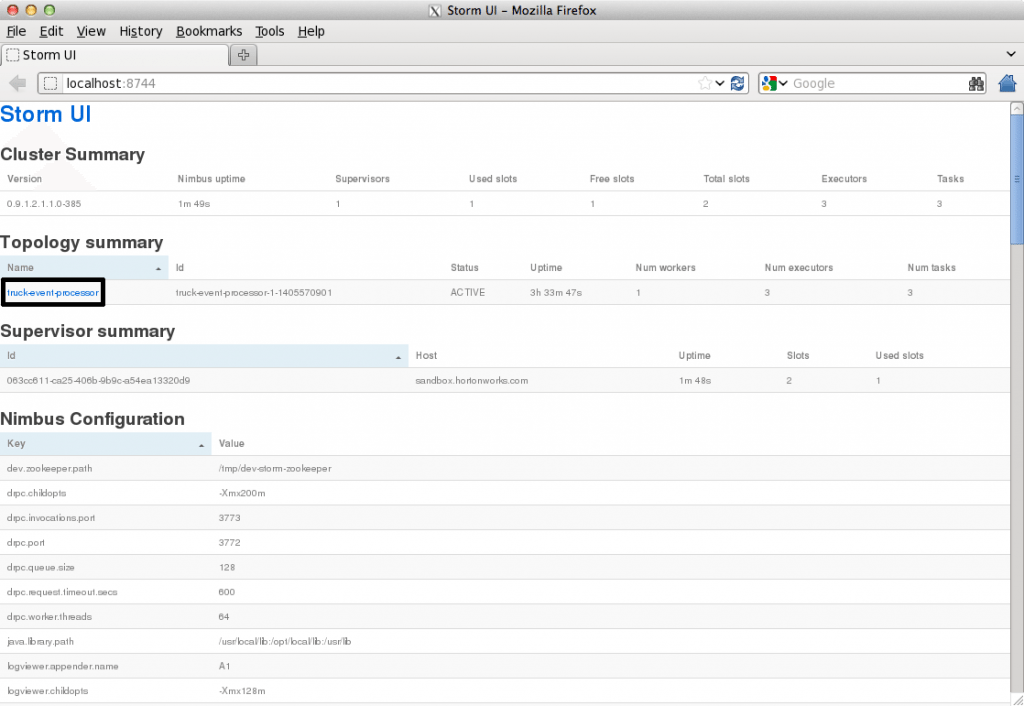 * Storm User View will now show a topology formed and running. 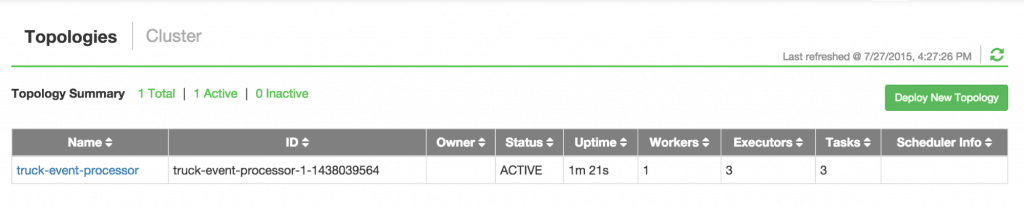 * **Generating TruckEvents** The TruckEvents producer can now be executed as we did in Tutorial #1 from the same dir: ```bash java -cp target/Tutorial-1.0-SNAPSHOT.jar com.hortonworks.tutorials.tutorial1.TruckEventsProducer sandbox.hortonworks.com:6667 sandbox.hortonworks.com:2181 ``` 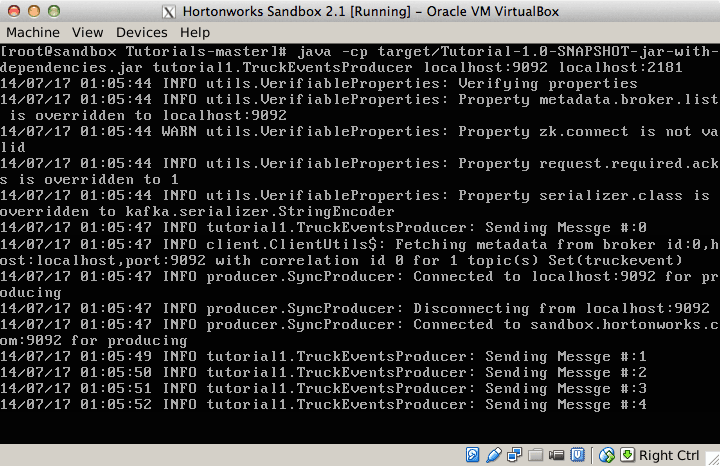 Go back to the Storm UI and click on “truck-event-processor” topology to drill into it. Under Spouts you should see that numbers of emitted and transferred tuples is increasing which shows that the messages are processed in real time by Spout  You can press Control-C to stop the Kafka producer (i.e keep Control key pressed and then press C) **Under Storm User view: ** You should be able to see the topology created by you under storm user views.  * You can also keep track of several statistics of Spouts and Bolts. 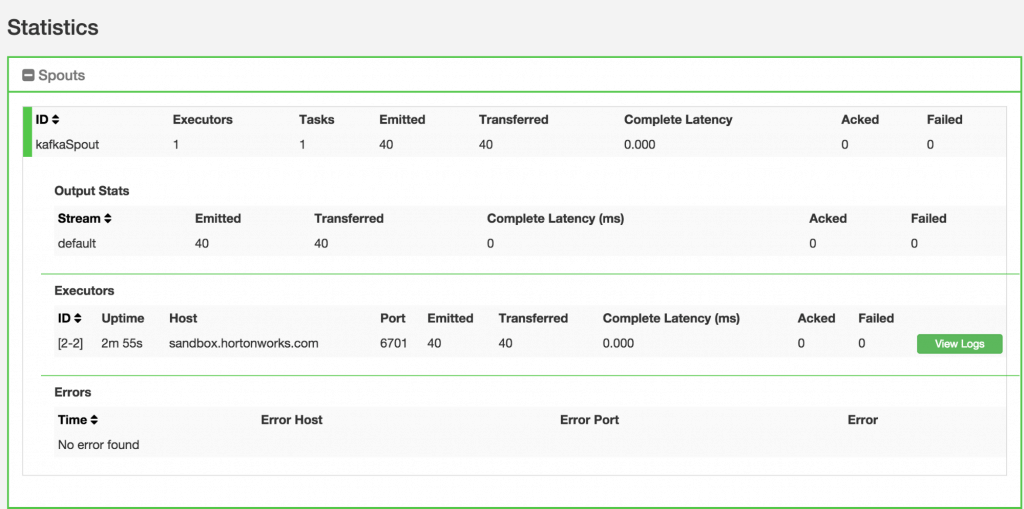  ####Step 3: Code description Let us review the code used in this tutorial. The source files are under the `/opt/TruckEvents/Tutorials-master/src/main/java/com/hortonworks/tutorials/tutorial2/` ``` [root@sandbox Tutorials-master]# ls -l src/main/java/com/hortonworks/tutorials/tutorial2/ total 16 -rw-r--r-- 1 root root 861 Jul 24 23:34 BaseTruckEventTopology.java -rw-r--r-- 1 root root 1205 Jul 24 23:34 LogTruckEventsBolt.java -rw-r--r-- 1 root root 2777 Jul 24 23:34 TruckEventProcessingTopology.java -rw-r--r-- 1 root root 2233 Jul 24 23:34 TruckScheme.java ``` * **BaseTruckEventTopology.java** ```java topologyConfig.load(ClassLoader.getSystemResourceAsStream(configFileLocation)); ``` Is the base class, where the topology configurations is initialized from the /resource/truck_event_topology.properties files. * **TruckEventProcessingTopology.java** This is the storm topology configuration class, where the Kafka spout and LogTruckevent Bolts are initialized. In the following method the Kafka spout is configured. ```java private SpoutConfig constructKafkaSpoutConf() { … @@ -308,11 +266,11 @@ In summary, refinery style data processing architecture enables you to: return spoutConfig; } ``` A logging bolt that prints the message from the Kafka spout was created for debugging purpose just for this tutorial. ```java public void configureLogTruckEventBolt(TopologyBuilder builder) { @@ -336,11 +294,13 @@ In summary, refinery style data processing architecture enables you to: conf, builder.createTopology()); } ``` * **TruckScheme.java** Is the deserializer provided to the kafka spout to deserialize kafka byte message stream to Values objects. ```java public List<Object> deserialize(byte[] bytes) { try @@ -365,12 +325,14 @@ In summary, refinery style data processing architecture enables you to: } } ``` * **LogTruckEventsBolt.java** LogTruckEvent spout logs the kafka message received from the kafka spout to the log files under `/var/log/storm/worker-*.log` ```java public void execute(Tuple tuple) { @@ -387,32 +349,8 @@ In summary, refinery style data processing architecture enables you to: tuple.getStringByField(TruckScheme.FIELD_LONGITUDE)); } ``` ###Conclusion In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence. -
Sep 1, 2015 . 1 changed file with 2 additions and 2 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -62,7 +62,7 @@ Each worker node runs a daemon called the “Supervisor.” It listens for work All coordination between Nimbus and the Supervisors is done through a [Zookeeper](http://zookeeper.apache.org/) cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This implies you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. Hence, Storm clusters are stable and fault-tolerant #### Streams The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics. @@ -93,7 +93,7 @@ Storm and Kafka naturally complement each other, and their powerful cooperation  #### Event Processing Pipeline  -
Sep 1, 2015 . 1 changed file with 2 additions and 0 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,3 +1,5 @@ # Processing realtime event stream with Apache Storm ### Introduction In this tutorial, we will explore [Apache Storm](http://hortonworks.com/hadoop/storm) and use it with [Apache Kafka](http://hortonworks.com/hadoop/kafka) to develop a multi-stage event processing pipeline. -
Sep 1, 2015 . 1 changed file with 21 additions and 21 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,10 +1,10 @@ ### Introduction In this tutorial, we will explore [Apache Storm](http://hortonworks.com/hadoop/storm) and use it with [Apache Kafka](http://hortonworks.com/hadoop/kafka) to develop a multi-stage event processing pipeline. ### Prerequisite In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored collecting and transporting data using Apache Kafka. So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed to proceed on to this tutorial. @@ -36,51 +36,51 @@ A storm cluster has three sets of nodes: * **ZooKeeper** nodes – coordinates the Storm cluster * **Supervisor** nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus 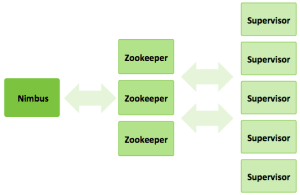 Five key abstractions help to understand how Storm processes data: * **Tuples** – an ordered list of elements. For example, a “4-tuple” might be (7, 1, 3, 7) * **Streams** – an unbounded sequence of tuples. * **Spouts** – sources of streams in a computation (e.g. a Twitter API) * **Bolts** – process input streams and produce output streams. They can run functions, filter, aggregate, or join data, or talk to databases. * **Topologies** – the overall calculation, represented visually as a network of spouts and bolts (as in the following diagram) 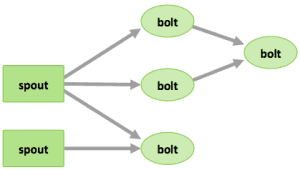 Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed onto to other bolts or stored in Hadoop. #### Storm Topologies A Storm cluster is similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs,” on Storm you run “topologies.” “Jobs” and “topologies” are different in that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you terminate it). There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “JobTracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures. Each worker node runs a daemon called the “Supervisor.” It listens for work assigned to its machine and starts and stops worker processes as dictated by Nimbus. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines. All coordination between Nimbus and the Supervisors is done through a [Zookeeper](http://zookeeper.apache.org/) cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This implies you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. Hence, Storm clusters are stable and fault-tolerant #### Streams Within Storm Topologies The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics. The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts.” Spouts and bolts have interfaces that you, as an application developer, implement to run your application-specific logic. A spout is a source of streams. For example, a spout may read tuples off of a Kafka Topic and emit them as a stream, or a spout may even connect to the Twitter API and emit a stream of tweets. A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts. Bolts can do anything from running functions, filtering tuples, do streaming aggregations, do streaming joins, talk to databases, and more. Networks of spouts and bolts are packaged into a “topology,” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream.  Links between nodes in your topology indicate how tuples should be passed around. For example, if there is a link between Spout A and Bolt B, a link from Spout A to Bolt C, and a link from Bolt B to Bolt C, then every time Spout A emits a tuple, it will send the tuple to both Bolt B and Bolt C. All of Bolt B’s output tuples will go to Bolt C as well. Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution. A topology runs indefinitely until you terminate it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. #### Apache Kafka on Storm An oil refinery takes crude oil, distills it, processes it and refines it into useful finished products such as the gas that we buy at the pump. We can think of Storm with Kafka as a similar refinery, but data is the input. A real-time data refinery converts raw streaming data into finished data products, enabling new use cases and innovative business models for the modern enterprise. @@ -91,14 +91,14 @@ Storm and Kafka naturally complement each other, and their powerful cooperation  #### Introduction to the Event Processing Pipeline  In an event processing pipeline, we can view each stage as a purpose-built step that performs some real-time processing against upstream event streams for downstream analysis. This produces increasingly richer event streams, as data flows through the pipeline: * _raw events_ stream from many sources, * those are processed to create _events of interest_, and * events of interest are analyzed to detect _significant events_. #### Building the Data Refinery with Topologies -
Sep 1, 2015 . 1 changed file with 2 additions and 2 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,6 +1,6 @@ ### Introduction In this tutorial, we will focus on [Apache Storm](http://hortonworks.com/hadoop/storm) and how we can use it with [Apache Kafka](http://hortonworks.com/hadoop/kafka) to develop a multi-stage event processing pipeline. ### Prerequisite @@ -10,7 +10,7 @@ So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://ho ### Scenario The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system takes into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criterions to alert and inform the management staff and the drivers themselves to mitigate risks. -
Sep 1, 2015 . 1 changed file with 0 additions and 6 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -24,12 +24,6 @@ Apache Storm is a distributed real-time computation system for processing large At the core of Storm’s data stream processing is a computational topology. This topology of nodes dictates how tuples are processed, transformed, aggregated, stored, or re-emitted to other nodes in the topology for further processing. #### Storm Cluster Components A storm cluster has three sets of nodes: -
Sep 1, 2015 . 1 changed file with 5 additions and 7 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,20 +1,18 @@ ### Introduction In this tutorial, we will focus on [Apache Storm](http://hortonworks.com/hadoop/storm) and how we can use it with [Apache Kafka](http://hortonworks.com/hadoop/kafka) to develop form a multi-stage event processing pipeline. ### Prerequisite In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored how to collect and transport data using Apache Kafka. So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed to proceed on to this tutorial. ### Scenario The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system takes into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criterions to alert and inform the management staff and the drivers themselves to mitigate risks. In this tutorial, you will learn the following topics: @@ -28,7 +26,7 @@ At the core of Storm’s data stream processing is a computational topology. Thi #### Storm on Apache Hadoop YARN Storm on YARN is powerful for scenarios requiring continuous analytics, real-time predictions, and continuous monitoring of operations. Eliminating a need to have dedicated data silos, enterprises using Storm on YARN benefit on cost savings (by accessing the same datasets as other engines and applications on the same cluster) and on security, data governance, and operations (by employing the same compute resources managed by YARN.  -
Sep 1, 2015 . 1 changed file with 5 additions and 5 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,20 +1,20 @@ ### Introduction In this tutorial, we will focus on [Apache Storm](http://hortonworks.com/hadoop/storm) and its relationship with [Apache Kafka](http://hortonworks.com/hadoop/kafka). We will describe how Storm and Kafka form a multi-stage event processing pipeline. ### Prerequisites In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored how to collect and transport data using Apache Kafka. So the tutorial [Transporting Realtime Event Stream with Apache Kafka](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed to proceed on this tutorial. ### Scenario The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system can take into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criteria to alert and inform the management staff and the drivers themselves when risk factors run high. In this tutorial you will use [**Apache Storm**](http://hortonworks.com/labs/storm/) on the Hortonworks Data Platform to capture these data events and process them in real time for further analysis. In this tutorial, you will learn the following topics: -
Sep 1, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,6 +1,6 @@ ### Introduction In this tutorial, we will focus on, [Apache Storm](http://hortonworks.com/hadoop/storm) and its relationship with [Apache Kafka](http://hortonworks.com/hadoop/kafka). We will describe how Storm and Kafka form a multi-stage event processing pipeline. ### Prerequisites -
Sep 1, 2015 . 1 changed file with 2 additions and 2 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -18,8 +18,8 @@ In this lab you will use [**Apache Storm**](http://hortonworks.com/labs/storm In this tutorial, you will learn the following topics: * Managing Storm on HDP. * Creating a Storm spout to consume the Kafka ‘truckevents’ generated in [Tutorial #1](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/). ### Concepts Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data in parallel and at scale. With its simple programming interface, Storm allows application developers to write applications that analyze streams comprised of tuples of data; a tuple may can contain object of any type. -
Sep 1, 2015 . 1 changed file with 1 addition and 1 deletion.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -4,7 +4,7 @@ In this tutorial, we will focus on one of those data processing engines, [Apache ### Prerequisites [Tutorial 1](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) needs to be completed. ### Scenario -
Sep 1, 2015 . 1 changed file with 32 additions and 34 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,15 +1,30 @@ ### Introduction In this tutorial, we will focus on one of those data processing engines, [Apache Storm](http://hortonworks.com/hadoop/storm) and its relationship with [Apache Kafka](http://hortonworks.com/hadoop/kafka). We will describe how Storm and Kafka form a multi-stage event processing pipeline. ### Prerequisites [Tutorial 1 should be completed successfully.](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) ### Scenario The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system can take into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criteria to alert and inform the management staff and the drivers themselves when risk factors run high. In the [previous tutorial](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/), we explored how to collect this data using Apache Kafka. In this lab you will use [**Apache Storm**](http://hortonworks.com/labs/storm/) on the Hortonworks Data Platform to capture these data events and process them in real time for further analysis. In this tutorial, you will learn the following topics: * Managing Storm on HDP. * Creating a Storm spout to consume the Kafka ‘truckevents’ generated in [Tutorial #1](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/). ### Concepts Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data in parallel and at scale. With its simple programming interface, Storm allows application developers to write applications that analyze streams comprised of tuples of data; a tuple may can contain object of any type. At the core of Storm’s data stream processing is a computational topology. This topology of nodes dictates how tuples are processed, transformed, aggregated, stored, or re-emitted to other nodes in the topology for further processing. #### Storm on Apache Hadoop YARN @@ -21,23 +36,23 @@ Storm on YARN is powerful for scenarios requiring continuous analytics, real-t A storm cluster has three sets of nodes: * **Nimbus node** (master node, similar to the Hadoop JobTracker): * Uploads computations for execution * Distributes code across the cluster * Launches workers across the cluster * Monitors computation and reallocates workers as needed * **ZooKeeper** nodes – coordinates the Storm cluster * **Supervisor** nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus  Five key abstractions help to understand how Storm processes data: * **Tuples**– an ordered list of elements. For example, a “4-tuple” might be (7, 1, 3, 7) * **Streams** – an unbounded sequence of tuples. * **Spouts** –sources of streams in a computation (e.g. a Twitter API) * **Bolts** – process input streams and produce output streams. They can run functions, filter, aggregate, or join data, or talk to databases. * **Topologies** – the overall calculation, represented visually as a network of spouts and bolts (as in the following diagram)  @@ -108,27 +123,10 @@ In summary, refinery style data processing architecture enables you to: * Tap into raw or refined data streams at any stage of the processing * Modularize your key cluster resources to most intense processing phase of the pipeline ###Steps ####Step 1: Start and Configure Storm** ** 1. View the Storm Services page** -
Sep 1, 2015 . 1 changed file with 22 additions and 147 deletions.There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -1,96 +1,22 @@ #### Introduction In this tutorial, we will focus on one of those data processing engines—[Apache Storm](http://hortonworks.com/hadoop/storm)—and its relationship with [Apache Kafka](http://hortonworks.com/hadoop/kafka). I will describe how Storm and Kafka form a multi-stage event processing pipeline, discuss some use cases, and explain Storm topologies. #### Goals of this tutorial: * Understanding Relationship between Apache Kafka and Apache Storm * Understanding Storm topologies Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data in parallel and at scale. With its simple programming interface, Storm allows application developers to write applications that analyze streams comprised of tuples of data; a tuple may can contain object of any type. At the core of Storm’s data stream processing is a computational topology, which is discussed below. This topology of nodes dictates how tuples are processed, transformed, aggregated, stored, or re-emitted to other nodes in the topology for further processing. #### Storm on Apache Hadoop YARN Storm on YARN is powerful for scenarios requiring continuous analytics, real-time predictions, and continuous monitoring of operations. Eliminating a need to have dedicated silos, enterprises using Storm on YARN benefit on cost savings (by accessing the same datasets as other engines and applications on the same cluster) and on security, data governance, and operations (by employing the same compute resources managed by YARN.  #### Storm Cluster Components A storm cluster has three sets of nodes: @@ -117,8 +43,6 @@ Five key abstractions help to understand how Storm processes data: Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed onto to other bolts or stored in Hadoop. #### Storm Topologies A Storm cluster is similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs,” on Storm you run “topologies.” “Jobs” and “topologies” are different — one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it). @@ -129,7 +53,7 @@ Each worker node runs a daemon called the “Supervisor.” It listens for wor All coordination between Nimbus and the Supervisors is done through a [Zookeeper](http://zookeeper.apache.org/) cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. Hence, Storm clusters are stable and fault-tolerant #### Streams Within Storm Topologies The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics. @@ -149,20 +73,7 @@ Each node in a Storm topology executes in parallel. In your topology, you can sp A topology runs forever, or until you kill it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. #### Concepts: Apache Kafka on Storm An oil refinery takes crude oil, distills it, processes it and refines it into useful finished products such as the gas that we buy at the pump. We can think of Storm with Kafka as a similar refinery, but data is the input. A real-time data refinery converts raw streaming data into finished data products, enabling new use cases and innovative business models for the modern enterprise. @@ -172,9 +83,8 @@ Storm and Kafka naturally complement each other, and their powerful cooperation  ####Introduction to the Event Processing Pipeline  @@ -184,15 +94,7 @@ In an event processing pipeline, we can view each stage as a purpose-built step * those are processed to create _events of interest_, and * events of interest are analyzed to detect _significant events_. #### Building the Data Refinery with Topologies To perform real-time computation on Storm, we create “topologies.” A topology is a graph of a computation, containing a network of nodes called “Spouts” and “Bolts.” In a Storm topology, a Spout is the source of data streams and a Bolt holds the business logic for analyzing and processing those streams. @@ -206,54 +108,27 @@ In summary, refinery style data processing architecture enables you to: * Tap into raw or refined data streams at any stage of the processing * Modularize your key cluster resources to most intense processing phase of the pipeline #### Scenario The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system can take into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criteria to alert and inform the management staff and the drivers themselves when risk factors run high. In Lab 1, you learned to collect this data using Apache Kafka. In this lab you will use [**Apache Storm**](http://hortonworks.com/labs/storm/) on the Hortonworks Data Platform to capture these data events and process them in real time for further analysis. In this tutorial, you will learn the following topics: * Managing Storm on HDP. * Creating a Storm spout to consume the Kafka ‘truckevents’ generated in [Tutorial #1](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/). ####Prerequisites [Tutorial 1 should be completed successfully.](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) ####Steps Step 1: Start and Configure Storm** ** 1. View the Storm Services page** @@ -548,4 +423,4 @@ In summary, refinery style data processing architecture enables you to: 1. Setup Ambari VNC service on the sandbox to enable remote desktop via VNC and install eclipse using steps here [https://github.com/hortonworks-gallery/ambari-vnc-service#setup-vnc-service](https://github.com/hortonworks-gallery/ambari-vnc-service#setup-vnc-service) 2. Import code as Eclipse project using steps here: [https://github.com/hortonworks-gallery/ambari-vnc-service#getting-started-with-storm-and-maven-in-eclipse-environment](https://github.com/hortonworks-gallery/ambari-vnc-service#getting-started-with-storm-and-maven-in-eclipse-environment) -
Sep 1, 2015 . 1 changed file with 0 additions and 0 deletions.There are no files selected for viewing
File renamed without changes. -
Sep 1, 2015 .There are no files selected for viewing
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode charactersOriginal file line number Diff line number Diff line change @@ -0,0 +1,551 @@ --- published: false title: Processing realtime event stream with Apache Storm layout: post --- #### **Introduction** Apache Storm is a distributed real-time computation system for processing large volumes of high-velocity data in parallel and at scale. With its simple programming interface, Storm allows application developers to write applications that analyze streams of tuples of data; a tuple may can contain object of any type. At the core of Storm’s data stream processing is a computational topology, which is discussed below. This topology of nodes dictates how tuples are processed, transformed,aggregated, stored, or re-emitted to other nodes in the topology for further processing. #### Goals of this module * Understanding Apache Storm architecture * Understanding Apache Storm Topologies #### Storm on Apache Hadoop YARN Storm on YARN is powerful for scenarios requiring continuous analytics, real-time predictions, and continuous monitoring of operations. Eliminating a need to have dedicated silos, enterprises using Storm on YARN benefit on cost savings (by accessing the same datasets as other engines and applications on the same cluster) and on security, data governance, and operations (by employing the same compute resources managed by YARN.  #### **Storm in the Enterprise** Some of the specific new business opportunities include: real-time customer service management, data monetization, operational dashboards, or cyber security analytics and threat detection. Storm is extremely fast, with the ability to process over a million records per second per node on a cluster of modest size. Enterprises harness this speed and combine it with other data access applications in Hadoop to prevent undesirable events or to optimize positive outcomes. Here are some typical “prevent” and “optimize” use cases for Storm. **“Prevent” Use Cases** **“Optimize” Use Cases** **Financial Services** * Securities fraud * Operational risks & compliance violations * Order routing * Pricing ** Telecom** * Security breaches * Network outages * Bandwidth allocation * Customer service ** Retail** * Shrinkage * Stock outs * Offers * Pricing ** Manufacturing** * Preventative maintenance * Quality assurance * Supply chain optimization * Reduced plant downtime ** Transportation** * Driver monitoring * Predictive maintenance * Routes * Pricing ** Web** * Application failures * Operational issues * Personalized content Five characteristics make Storm ideal for real-time data processing workloads. Storm is: * **Fast** – benchmarked as processing one million 100 byte messages per second per node * **Scalable** – with parallel calculations that run across a cluster of machines * **Fault-tolerant** – when workers die, Storm will automatically restart them. If a node dies, the worker will be restarted on another node. * **Reliable** – Storm guarantees that each unit of data (tuple) will be processed at least once or exactly once. Messages are only replayed when there are failures. * **Easy to operate** – standard configurations are suitable for production on day one. Once deployed, Storm is easy to operate. #### **How Storm Works-** #### Storm Cluster Components A storm cluster has three sets of nodes: * **Nimbus node** (master node, similar to the Hadoop JobTracker): * Uploads computations for execution * Distributes code across the cluster * Launches workers across the cluster * Monitors computation and reallocates workers as needed * **ZooKeeper** nodes – coordinates the Storm cluster * **Supervisor** nodes – communicates with Nimbus through Zookeeper, starts and stops workers according to signals from Nimbus  Five key abstractions help to understand how Storm processes data: * **Tuples**– an ordered list of elements. For example, a “4-tuple” might be (7, 1, 3, 7) * **Streams** – an unbounded sequence of tuples. * **Spouts** –sources of streams in a computation (e.g. a Twitter API) * **Bolts** – process input streams and produce output streams. They can run functions, filter, aggregate, or join data, or talk to databases. * **Topologies** – the overall calculation, represented visually as a network of spouts and bolts (as in the following diagram)  Storm users define topologies for how to process the data when it comes streaming in from the spout. When the data comes in, it is processed and the results are passed onto to other bolts or stored in Hadoop. Learn more about how the community is working to [integrate Storm with Hadoop](http://hortonworks.com/labs/storm) and improve its readiness for the enterprise. #### Storm Topologies A Storm cluster is similar to a Hadoop cluster. Whereas on Hadoop you run “MapReduce jobs,” on Storm you run “topologies.” “Jobs” and “topologies” are different — one key difference is that a MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it). There are two kinds of nodes on a Storm cluster: the master node and the worker nodes. The master node runs a daemon called “Nimbus” that is similar to Hadoop’s “JobTracker”. Nimbus is responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures. Each worker node runs a daemon called the “Supervisor.” It listens for work assigned to its machine and starts and stops worker processes as dictated by Nimbus. Each worker process executes a subset of a topology; a running topology consists of many worker processes spread across many machines. All coordination between Nimbus and the Supervisors is done through a [Zookeeper](http://zookeeper.apache.org/) cluster. Additionally, the Nimbus daemon and Supervisor daemons are fail-fast and stateless; all state is kept in Zookeeper or on local disk. This means you can kill -9 Nimbus or the Supervisors and they’ll start back up like nothing happened. Hence, Storm clusters are stable and fault-tolerant #### **Streams Within Storm Topologies** The core abstraction in Storm is the “stream.” It is an unbounded sequence of tuples. Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. For example, you may transform a stream of tweets into a stream of trending topics. The basic primitives Storm provides for doing stream transformations are “spouts” and “bolts.” Spouts and bolts have interfaces that you, as an application developer, implement to run your application-specific logic. A spout is a source of streams. For example, a spout may read tuples off of a Kafka Topics and emit them as a stream. Or a spout may connect to the Twitter API and emit a stream of tweets. A bolt consumes any number of input streams, does some processing, and possibly emits new streams. Complex stream transformations, like computing a stream of trending topics from a stream of tweets, require multiple steps and thus multiple bolts. Bolts can do anything from run functions, filter tuples, do streaming aggregations, do streaming joins, talk to databases, and more. Networks of spouts and bolts are packaged into a “topology,” which is the top-level abstraction that you submit to Storm clusters for execution. A topology is a graph of stream transformations where each node is a spout or bolt. Edges in the graph indicate which bolts are subscribing to which streams. When a spout or bolt emits a tuple to a stream, it sends the tuple to every bolt that subscribed to that stream.  Links between nodes in your topology indicate how tuples should be passed around. For example, if there is a link between Spout A and Bolt B, a link from Spout A to Bolt C, and a link from Bolt B to Bolt C, then every time Spout A emits a tuple, it will send the tuple to both Bolt B and Bolt C. All of Bolt B’s output tuples will go to Bolt C as well. Each node in a Storm topology executes in parallel. In your topology, you can specify how much parallelism you want for each node, and then Storm will spawn that number of threads across the cluster to do the execution. A topology runs forever, or until you kill it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. ## Concepts: Apache Kafka on Storm #### **Introduction** Hortonworks Data Platform’s YARN-based architecture enables multiple applications to share a common cluster and data set while ensuring consistent levels of response made possible by a centralized architecture. Hortonworks led the efforts to on-board open source data processing engines, such as [Apache Hive](http://hortonworks.com/hadoop/hive), [HBase](http://hortonworks.com/hadoop/hbase), [Accumulo](http://hortonworks.com/hadoop/accumulo), [Spark](http://hortonworks.com/hadoop/spark),[Storm](http://hortonworks.com/hadoop/storm) and others, on [Apache Hadoop YARN](http://hortonworks.com/hadoop/yarn). In this tutorial, we will focus on one of those data processing engines—[Apache Storm](http://hortonworks.com/hadoop/storm)—and its relationship with [Apache Kafka](http://hortonworks.com/hadoop/kafka). I will describe how Storm and Kafka form a multi-stage event processing pipeline, discuss some use cases, and explain Storm topologies. #### **Goals of this tutorial:** * Understanding Relationship between Apache Kafka and Apache Storm * Understanding Storm topologies **Kafka on Storm** An oil refinery takes crude oil, distills it, processes it and refines it into useful finished products such as the gas that we buy at the pump. We can think of Storm with Kafka as a similar refinery, but data is the input. A real-time data refinery converts raw streaming data into finished data products, enabling new use cases and innovative business models for the modern enterprise. Apache Storm is a distributed real-time computation engine that reliably processes unbounded streams of data. While Storm processes stream data at scale, Apache Kafka processes messages at scale. Kafka is a distributed pub-sub real-time messaging system that provides strong durability and fault tolerance guarantees. Storm and Kafka naturally complement each other, and their powerful cooperation enables real-time streaming analytics for fast-moving big data. HDP 2.3 contains the results of Hortonworks’ continuing focus on making the Storm-Kafka union even more powerful for stream processing.  **Conceptual Introduction to the Event Processing Pipeline**  In an event processing pipeline, we can view each stage as a purpose-built step that performs some real-time processing against upstream event streams for downstream analysis. This produces increasingly richer event streams, as data flows through the pipeline: * _raw events_ stream from many sources, * those are processed to create _events of interest_, and * events of interest are analyzed to detect _significant events_. Here are some typical uses for this event processing pipeline: * a. High Speed Filtering and Pattern Matching * b. Contextual Enrichment on the Fly * c. Real-time KPIs, Statistical Analytics, Baselining and Notification * d. [Predictive Analytics](http://hortonworks.com/solutions/advanced-analytic-apps/#predictive-analytics) * e. Actions and Decisions #### **Building the Data Refinery with Topologies** To perform real-time computation on Storm, we create “topologies.” A topology is a graph of a computation, containing a network of nodes called “Spouts” and “Bolts.” In a Storm topology, a Spout is the source of data streams and a Bolt holds the business logic for analyzing and processing those streams.  Hortonworks’ focus for Apache Storm and Kafka has been to make it easier for developers to ingest and publish data streams from Storm topologies. The first topology ingests raw data streams from Kafka and fans out to HDFS, which serves as persistent store for raw events. Next, a filter Bolt emits the enriched event to a downstream Kafka Bolt that publishes it to a Kafka Topic. As events flow through these stages, the system can keep track of data lineage that allows drill-down from aggregated events to its constituents and can be used for forensic analysis. In a multi-stage pipeline architecture, providing right cluster resources to most intense part of the data processing stages is very critical, an “Isolation Scheduler” in Storm provides the ability to easily and safely share a cluster among many topologies. In summary, refinery style data processing architecture enables you to: * Incrementally add more topologies/use cases * Tap into raw or refined data streams at any stage of the processing * Modularize your key cluster resources to most intense processing phase of the pipeline #### Ingesting and processing Real-time events with Apache Storm #### **Introduction** The Trucking business is a high-risk business in which truck drivers venture into remote areas, often in harsh weather conditions and chaotic traffic on a daily basis. Using this solution illustrating Modern Data Architecture with Hortonworks Data Platform, we have developed a centralized management system that can help reduce risk and lower the total cost of operations. This system can take into consideration adverse weather conditions, the driver’s driving patterns, current traffic conditions and other criteria to alert and inform the management staff and the drivers themselves when risk factors run high. In Lab 1, you learned to collect this data using Apache Kafka. In this lab you will use [**Apache Storm**](http://hortonworks.com/labs/storm/) on the Hortonworks Data Platform to capture these data events and process them in real time for further analysis. In this tutorial, you will learn the following topics: * Managing Storm on HDP. * Creating a Storm spout to consume the Kafka ‘truckevents’ generated in [Tutorial #1](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/). **Prerequisites** [Lab 1 should be completed successfully.](http://hortonworks.com/hadoop-tutorial/simulating-transporting-realtime-events-stream-apache-kafka/#section_5) **Outline** * Introduction * Prerequisites * Apache Storm basics * Step 1: Apache Storm Configurations * Step 2: Creating Storm Topology * Step 3: Code Review **Apache Storm** Apache Storm is an Open Source distributed, reliable, fault tolerant system for real time processing of data at high velocity. It’s used for: * Real time analytics * Online machine learning * Continuous statics computations * Operational Analytics * And, to enforce Extract, Transform, and Load (ETL) paradigms. Spout and Bolt are the two main components in Storm, which work together to process streams of data. * Spout: Works on the source of data streams. In the “Truck Events” use case, Spout will read data from Kafka “truckevent” topics. * Bolt: Spout passes streams of data to Bolt which processes and persists passes it to either a data store or sends it downstream to another Bolt. **Step 1: Start and Configure Storm** ** 1. View the Storm Services page** Started by logging into Ambari as admin/admin. From the Dashboard page of Ambari, click on Storm from the list of installed services. (If you do not see Storm listed under Services, please follow click on Action->Add Service and select Storm and deploy it.)  ** 2. Start Storm** From the Storm page, click on Service Actions -> Start  Check the box and click on Confirm Start:  Wait for Storm to start.  ** 3. Configure Storm** You can check the below configurations by pasting them into the Filter text box under the Service Actions dropdown * Check zookeeper configuration: ensure **storm.zookeeper.servers** is set to **sandbox.hortonworks.com**  * Check the local directory configuration: ensure **storm.local.dir** is set to **/hadoop/storm**  * Check the nimbus host configuration: ensure nimbus.host is set to sandbox.hortonworks.com  * Check the slots allocated: ensure supervisor.slots.ports is set to [6700, 6701]  * Check the UI configuration port: Ensure ui.port is set to 8744  * #### Check the Storm UI from the Quick Links  Now you can see the UI:  **4.** **Storm User View: **You can alternatively use Storm User View as well to view the topologies created by you. * Go to the Ambari User VIew icon and select Storm :  * The Storm user view gives you the summary of topologies created by you. As of now we do not have any topologies created hence none are listed in the summary.  #### **Step 2. Creating a Storm Spout to consume the Kafka truck events generated in Tutorial #1** * #### ****Load data if required:**** From tutorial #1 you already have the required [New York City truck routes](http://www.nyc.gov/html/dot/downloads/misc/all_truck_routes_nyc.kml) KML. If required, you can download the latest copy of the file with the following command. [root@sandbox ~]# wget http://www.nyc.gov/html/dot/downloads/misc/all_truck_routes_nyc.kml --directory-prefix=/opt/TruckEvents/Tutorials-master/src/main/resources/ Recall that the source code is under /opt/TruckEvents/Tutorials-master/src directory and pre-compiled jars are under the /opt/TruckEvents/Tutorials-master/target directory **(Optional)** If you would like to modify/run the code: * refer to Appendix A at the end of the tutorial for the steps to run maven to compile the jars to the target subdir from terminal command line * refer to Appendix B at the end of the tutorial for the steps to enable VNC (i.e. ‘remote desktop’) access on your sandbox and open/compile the code using Eclipse * #### ****Verify that Kafka process is running**** Verify that Kafka is running using Ambari dashboard. If not, following the steps in tutorial #1  * #### ****Creating Storm Topology**** We now have ‘supervisor’ daemon and Kafka processes running. To do real-time computation on Storm, you create what are called “topologies”. A topology is a graph of computation. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes. Running a topology is straightforward. First, you package all your code and dependencies into a single jar. Then, you run a command like the following: The command below will start a new Storm Topology for TruckEvents. [root@sandbox ~]# cd /opt/TruckEvents/Tutorials-master/ [root@sandbox ~]# storm jar target/Tutorial-1.0-SNAPSHOT.jar.com.hortonworks.tutorials.tutorial2.TruckEventProcessingTopology  It should complete with “Finished submitting topology” as shown below.  This runs the class TruckEventProcessingTopology .The main function of the class defines the topology and submits it to Nimbus. The storm jar part takes care of connecting to Nimbus and uploading the jar. Refresh the Storm UI browser window to see new Topology ‘truck-event-processor’ in the browser.  * Storm User View will now show a topology formed and running.  * #### ****Generating TruckEvents**** The TruckEvents producer can now be executed as we did in Tutorial #1 from the same dir: root@sandbox Tutorials-master]java -cp target/Tutorial-1.0-SNAPSHOT.jar com.hortonworks.tutorials.tutorial1.TruckEventsProducer sandbox.hortonworks.com:6667 sandbox.hortonworks.com:2181  Go back to the Storm UI and click on “truck-event-processor” topology to drill into it. Under Spouts you should see that numbers of emitted and transferred tuples is increasing which shows that the messages are processed in real time by Spout  You can press Control-C to stop the Kafka producer (i.e keep Control key pressed and then press C) **Under Storm User view: **You should be able to see the topology created by you under storm user views.  * You can also keep track of several statistics of Spouts and Bolts.  ####  #### #### **Step 3: Code description** Let us review the code used in this tutorial. The source files are under the /opt/TruckEvents/Tutorials-master/src/main/java/com/hortonworks/tutorials/tutorial2/ [root@sandbox Tutorials-master]# ls -l src/main/java/com/hortonworks/tutorials/tutorial2/ total 16 -rw-r--r-- 1 root root 861 Jul 24 23:34 BaseTruckEventTopology.java -rw-r--r-- 1 root root 1205 Jul 24 23:34 LogTruckEventsBolt.java -rw-r--r-- 1 root root 2777 Jul 24 23:34 TruckEventProcessingTopology.java -rw-r--r-- 1 root root 2233 Jul 24 23:34 TruckScheme.java * #### ****BaseTruckEventTopology.java**** topologyConfig.load(ClassLoader.getSystemResourceAsStream(configFileLocation)); Is the base class, where the topology configurations is initialized from the /resource/truck_event_topology.properties files. #### **TruckEventProcessingTopology.java** This is the storm topology configuration class, where the Kafka spout and LogTruckevent Bolts are initialized. In the following method the Kafka spout is configured. private SpoutConfig constructKafkaSpoutConf() { … SpoutConfig spoutConfig = new SpoutConfig(hosts, topic, zkRoot, consumerGroupId); … spoutConfig.scheme = new SchemeAsMultiScheme(new TruckScheme()); return spoutConfig; } A logging bolt that prints the message from the Kafka spout was created for debugging purpose just for this tutorial. public void configureLogTruckEventBolt(TopologyBuilder builder) { LogTruckEventsBolt logBolt = new LogTruckEventsBolt(); builder.setBolt(LOG_TRUCK_BOLT_ID, logBolt).globalGrouping(KAFKA_SPOUT_ID); } The topology is built and submitted in the following method; private void buildAndSubmit() throws Exception { ... StormSubmitter.submitTopology("truck-event-processor", conf, builder.createTopology()); } * #### ****TruckScheme.java**** Is the deserializer provided to the kafka spout to deserialize kafka byte message stream to Values objects. public List<Object> deserialize(byte[] bytes) { try { String truckEvent = new String(bytes, "UTF-8"); String[] pieces = truckEvent.split("\\|"); Timestamp eventTime = Timestamp.valueOf(pieces[0]); String truckId = pieces[1]; String driverId = pieces[2]; String eventType = pieces[3]; String longitude= pieces[4]; String latitude = pieces[5]; return new Values(cleanup(driverId), cleanup(truckId), eventTime, cleanup(eventType), cleanup(longitude), cleanup(latitude)); } catch (UnsupportedEncodingException e) { LOG.error(e); throw new RuntimeException(e); } } * #### ****LogTruckEventsBolt.java**** LogTruckEvent spout logs the kafka message received from the kafka spout to the log files under /var/log/storm/worker-*.log public void execute(Tuple tuple) { LOG.info(tuple.getStringByField(TruckScheme.FIELD_DRIVER_ID) + "," + tuple.getStringByField(TruckScheme.FIELD_TRUCK_ID) + "," + tuple.getValueByField(TruckScheme.FIELD_EVENT_TIME) + "," + tuple.getStringByField(TruckScheme.FIELD_EVENT_TYPE) + "," + tuple.getStringByField(TruckScheme.FIELD_LATITUDE) + "," + tuple.getStringByField(TruckScheme.FIELD_LONGITUDE)); } **Conclusion** In this tutorial we have learned to capture data from Kafka Producer into Storm Spout. This data can now be processed in real time. In our next Tutorial, using Storm Bolt, you will see how to store data into multiple sources for persistence. **Appendix A: Compile Storm topology from command line** Compile the code using Maven after downloading a new data file or on completing any changes to the code under /opt/TruckEvents/Tutorials-master/src directory. [root@sandbox ~]# cd /opt/TruckEvents/Tutorials-master/ [root@sandbox ~]# mvn clean package mvn clean package mvn build success We now have a successfully compiled the code. **Appendix B: Enabling remote desktop on sandbox and setting up Storm topology as Eclipse project** 1. Setup Ambari VNC service on the sandbox to enable remote desktop via VNC and install eclipse using steps here [https://github.com/hortonworks-gallery/ambari-vnc-service#setup-vnc-service](https://github.com/hortonworks-gallery/ambari-vnc-service#setup-vnc-service) 2. Import code as Eclipse project using steps here: [https://github.com/hortonworks-gallery/ambari-vnc-service#getting-started-with-storm-and-maven-in-eclipse-environment](https://github.com/hortonworks-gallery/ambari-vnc-service#getting-started-with-storm-and-maven-in-eclipse-environment)