- Raftという分散合意アルゴリズムの紹介
- 論文: In Search of an Understandable Consensus ALgorithm (Extended Version)
- Raft三日目くらいの人が自分の理解をもとに(適当に)書いています
- いつも通り用語の使い方は怪しい
- Raftと分散合意のどちらも特別詳しい訳ではないので、ちゃんと知りたい人は上記論文や他の説明を参照することを推奨します
- 分散合意アルゴリズム
- Paxos(おそらく有名な分散合意アルゴリズム)の改良版的な位置づけ(?)
- 機能追加や性能向上ではなく__理解可能性__の改善
- etcdというCoreOS/Dockerをクラスタ化するためのツールで採用されているのが有名?
- 詳しくは知らないですが...
クラスタ内の全サーバに一貫性のあるステートマシンを提供するためのアルゴリズム(?):
- 全サーバからアクセス可能な、安全/可用/アトミックな共有オブジェクト的なものが利用可能になる
- 並列・分散したリクエスト群の線形化とログへの保存を行い、そのログに全サーバが合意することで一貫性を保つ
- ! Raftの場合の話と一般的な話の切り分けが不十分
イメージ図 (見返してみると、論文のFigure1とかなり似ていた...):
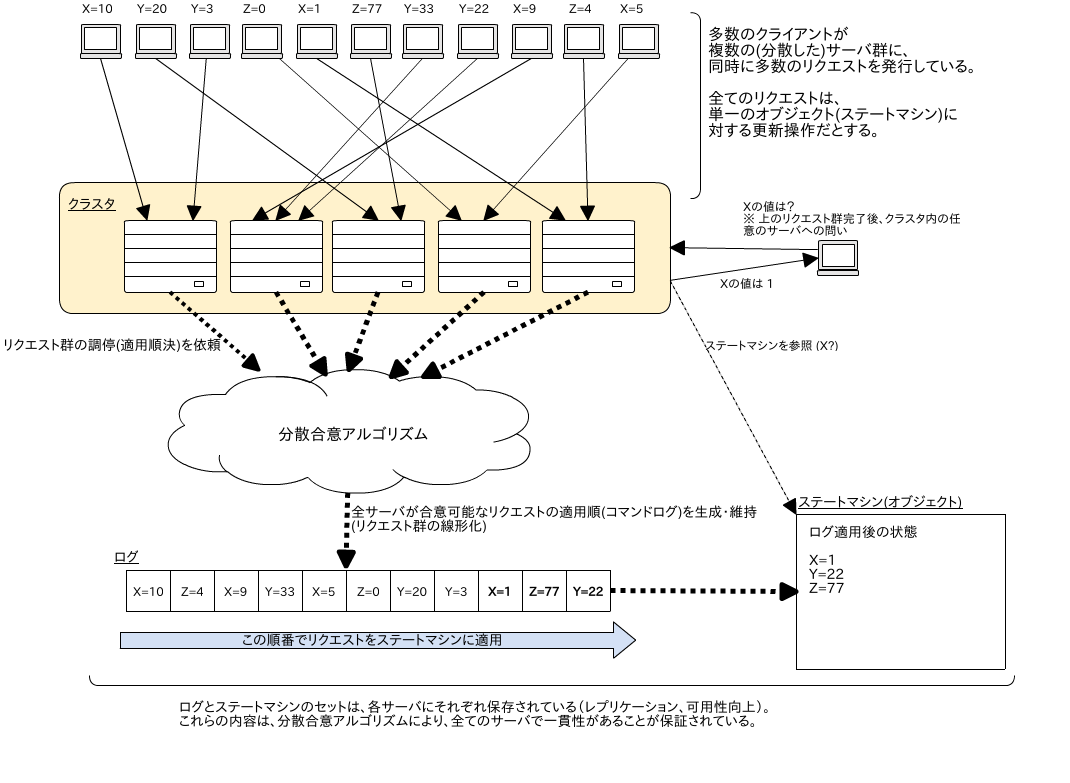
実用的な分散合意アルゴリズムは典型的には以下の性質を備えている(らしい):
- 安全性を保証する:
- 決して間違った結果は返さない
- under all non-Byzantine conditions
- ex. ネットワーク遅延、分断、パケットロス、再送、順序入れ替わり
- 高可用性:
- サーバの__過半数__が生存してさえいれば全機能を提供可能
- ex. 5台中2台がダウンしても問題なく動く
- サーバ再起動(and クラスタへの再参加)にも対応可能
- 一部の遅いサーバによって、全体の応答性が下がることはない(通常ケースでは)
- サーバの__過半数__が生存してさえいれば全機能を提供可能
- タイミング問題は整合性には影響を与えない
- ex. 不正な時計、極端なメッセージ遅延
- 最悪でも可用性を損なうだけ
論文では、Paxosは難しすぎる、というのが前提としてある:
- 理論的(?)には良い
- 熟練のリサーチャーでも説明が困難、著者たちもちゃんと理解するのに一年近く掛かった、とか
- その他、何故問題なのかがつらつらと(省略)
- また、現実の実装にそのまま適用できないので、各人が手を入れるしかなく、実ライブラリの理論的な正しさの証明が困難
Raftは__理解可能性__を最重視:
- Paxosに比べて何かが強力とかではなく__理解可能性__を大幅に向上させたけど、有用な性質は維持しています、という方向性の主張
- 方針選択に悩んだら説明が容易な方を採用
- そのため若干制約が増えてしまった箇所もあるが実用上は問題ないとのこと
- 実装への適用も容易
- 厳密な(?)証明も別途ある(!未読): Safety Proof and Formal Specification for Raft
- 実際に論文は分かりやすかった
- 実装への適用も結構素直に行えた
- https://github.com/sile/rafte (半日、1000行程度。コードの質はアレですが...)
- モデルがシンプル:
- 三つの独立した問題に分割 (リーダー選出、ログレプリケーション、安全性)
- 強いリーダーを採用することで、サーバ間な複雑なやりとりを回避
- サーバ間のやりとりで使うプロトコル(RPCと呼称)は、二種類だけ
投票要求RPC(RequestVote)とログエントリ追加RPC(AppendEntries)- ※後述のログ圧縮も実装するならもう一つ増える
- 上に載せた実用的な分散合意アルゴリズムが備えるべき性質を備えている (ので実用的)
- ex. 半分までならクラスタ内のサーバが落ちたりしても大丈夫
- メンバー設定の動的更新にも対応
- ただしクラスタの設定は、全メンバーが共有している必要がある (ex. __過半数__の判断に必要等)
若干不正確かもしれないですが、一応必要最低限の用語定義:
- コマンド:
- クライアントから発行され、(最終的に)ステートマシンに適用される一つの(更新)操作
- ログのエントリ
- ログ:
- コマンドの適用履歴(適用順)
- 再起動に備えて、ログ内の全エントリは、安定ストレージに保存される
- インデックス:
- ログ内の各エントリの添字
- 1から始まる (古いエントリ => 新しいエントリ)
- term (期間?):
- Raftの論理時間
- 単調増加
- リーダー選出の度にインクリメントされる
- リーダー選出開始から、選ばれたリーダーの任期が終わるまでが一つのterm
{インデックス、term}のペアで、ログのエントリを一意に特定するキーとなる
ログの図(論文のFigure6より):

termの図(論文のFigure5より):

NOTE: 後で再び触れるので、ここは項目名を読むくらいで飛ばす
- [1] 選出安全性 (Election Safety):
- 一つのtermでは、最大で一つのリーダーが選出される
- ! 0はあっても、2以上はない
- [2] リーダーは追記のみ (Leader Append-Only):
- リーダーは自身のログの上書きや削除は行わない
- 新しいエントリの追加のみを行う
- [3] ログマッチング (Log Matching):
- 二つのログが同じ
{インデックス、term}のペアを保持しているなら、先頭からそのインデックスに至るまでの全てのエントリは等しい
- 二つのログが同じ
- [4] リーダー完全性 (Leader Completeness):
- あるterm(A)でログエントリがコミットされたとする、
- そのエントリは、Aより大きな数値のtermのリーダーのログに含まれている
- ! 要は一度コミットされたエントリは消えない
- [5] ステートマシン安全性 (State Machine Safety):
- あるサーバが、あるインデックスのログエントリを、ステートマシンに適用したとする、
- 別のサーバで、インデックスは同じだが内容が異なるエントリがステートマシンに適用されることはない
- ! 全サーバのステートマシンの状態が等しくなることを保証
以下の三つのサブ問題に分割されている:
- リーダー選出 (Leader Election)
- 一貫性の担保(?)
- ログレプリケーション (Log Replication)
- 可用性の担保(?)
- 安全性 (Safety)
- 上記、二つに制限を追加することで、厳密な安全性を保証
補足:
- 各サーバの役割(ステート)には
leader、candidate、followerの三つがある - 詳しくは「選出方法」の箇所で
Raftはリーダーに強い役割を割当てることでモデルを単純にしている:
- リーダーになれるサーバは、一度に最大で一つ
- クライアントからのリクエストを処理するのはリーダーのみ
- リーダーのログがマスター (改変されず、追記のみ)
- ログエントリのデータフローは
leader => followerの流れしかない(一方通行)
つまり、一度リーダーが選出されると、
- 基本的に、各種操作はそのリーダーに対して行われる (単一サーバに集中するので整合性の維持が容易)
- リーダー以外(candidate,follower)は、ログ同期用のメッセージ(AppendEntriesRPC)をリーダーから受け取るのみ
- AppendEntriesRPCは、ハートビートの役割も兼ねる
基本的には多数決(majority)ルール:
-
follower=>candidateにステートが変わったサーバが選出処理を始める (遷移条件は後述)
-
- まず、自分のtermをインクリメントする
-
- RequestVoteRPCを全サーバにブロードキャスト
-
- 過半数以上の得票(レスポンス)を受け取った時点で
leaderになる
- 過半数以上の得票(レスポンス)を受け取った時点で
-
- その後は定期的にハートビート(空のAppendEntriesRPC)をブロードキャストすることで
leaderを維持
- その後は定期的にハートビート(空のAppendEntriesRPC)をブロードキャストすることで
票が割れたらどうするか?
- 状況: 二つの
candidateサーバが同時にRequestVoteRPCをブロードキャストした場合等に発生する可能性あり - タイムアウト時間を過ぎても過半数に達しなかった場合は、ウェイトを入れてリトライする
- リトライ時にはtermが再度インクリメントされるので、リーダーが一人もいないtermができる
- その際にウェイト時間を乱数(例えば150ms〜300msのいずれか)を使って決定することで、衝突が繰り返される可能性を極めて小さくしている
- (もっと複雑な衝突解決ではなく)乱数ウェイトを採用したのは理解可能性を重視して
競合者がいなくてもリジェクトされることがある:
- 自分よりも大きなtermをもつサーバがいた場合
- 自分が古い証拠なので、
followerにステートが遷移する(後述)
この選出方法は[1] 選出安全性を保証する:
- 一つのtermでは、最大で一つのリーダーが選出される
- ! 過半数が選出条件なので、二つ以上が同時にリーダーになることはありえない
参考サイト: http://thesecretlivesofdata.com/raft/
follower、candidate、leaderのステートがどう遷移するか。
※ 末尾の遷移図を見れば十分
サーバの起動直後はfollower:
- 一定時間、いずれのRPCも受信しなかったら、
candidateになる(選出処理の開始)- RPCを受信しない = リーダーダウン or リーダー候補がいない
candidateサーバは上述の選出処理を行い:
- 以下のいずれかで
followerになる。- 別のサーバが先に
leaderに選ばれた - 自分よりも新しいtermを持つサーバからのRPC(or RPC応答)を受信した
- 別のサーバが先に
- リーダーに選ばれたなら
leaderになる - 選出処理がタイムアウトしたら、
candidateのままで(ウェイト後に)リトライする
leaderは:
- 自分よりも新しいtermを持つサーバからのRPC(or RPC応答)を受信したら
followerになるcandidateの時と同様に、自分よりも新しい(時間/termが進んでいる)のサーバがいたら、一度followerになる- 定期的にハートビートがブロードキャストできていれば、通常は
leader状態が維持される
ステート遷移の図(論文のFigure4):

可用性をあげるためにはレプリケーションが必要。
ログのサーバ間での一貫性をどう維持するかが問題:
leaderのログがマスター- 例えば以下のケースで
followerとの間で差異(齟齬)が生じ得る:leaderがクライアントからのリクエスト(コマンド)を受けて、ログにエントリを追加したfollowerが何らかの理由で(RPC通信に)極端に遅延しているfollowerのダウンからの復帰直後 (起動後はまずストレージに保存されたログを読み込む)leaderになった直後- 過去の地点でログが分岐していることもある (下の図の
(a)と(f)) - ! コミット済みのログに関しては分岐はありえない
- 過去の地点でログが分岐していることもある (下の図の
- 何らかの方法で同期(
leaderに追従)が必要
leaderとfollowerで差異が生じる例 (論文のFigure7):

クライアントからのリクエスト(コマンド)をどう処理するか(正常系?):
-
- リーダーが受ける
-
- リーダーのログにエントリ追加
-
- 追加エントリを
followerにブロードキャスト (AppendEntriesRPC)
- NOTE: AppendEntriesRPCは、一エントリずつだけでなく、複数まとめて送信することも可能
- 追加エントリを
-
- __過半数以上__からエントリを保存したとのRPC応答があれば、以下を実行
- 過半数に達するまでは、リトライ and 待機
-
- リーダーのログエントリをコミット (次回の以降のrpcで
followerにもコミットを反映)
- リーダーのログエントリをコミット (次回の以降のrpcで
-
- コミットが完了したら、クライアントに応答
正常系以外は?
followerのログが先に進みすぎ、後ろ過ぎ- 共通祖先を探して、その地点以降を、リーダーの内容で上書き
- RPCが失敗したり応答がない
followerはどうする?- リーダーが定期的にリトライし続ける
- 重要なのは、コミット済み(= クライアントが見たことがある)の地点のエントリは決して改変されない、ということ
- ! ある地点をコミットしたら、それより前のエントリも全てコミットされる
このレプリケーション方法は[2] リーダーは追記のみと[3] ログマッチングを保証する:
- [2] リーダーは追記のみ (Leader Append-Only):
- リーダーは自身のログの上書きや削除は行わない
- 新しいエントリの追加のみを行う
- [3] ログマッチング (Log Matching):
- 二つのログが同じ
{インデックス、term}のペアを保持しているなら、先頭からそのインデックスに至るまでの全てのエントリは等しい
- 二つのログが同じ
上の二節で取り上げた方法はかなりシンプル and アルゴリズムの外観を掴むには十分。
ただし、
- 実際には、これだけだと安全性が崩れるケースがある
- そのため、以下のような制約を追加する必要がある
- 選出制限
- 一つ前の期間のコミット中のエントリ群 (コミットが破棄される可能性をなくす)
- Commting entries from previous terms
{インデックス, term}の大小比較もします、という話:
candidateのログが、他のマジョリティのそれと同じくらい進んでいることを保証したいのでインデックスも加味する- 上記条件が満たせるなら、新しいリーダーは、(選出された際に)全てのコミット済みのログを含んでいるはず
- コミット対称のログエントリは「現在のtermと一致するもの」のみ
- コミットされたエントリが上書きされるの防ぐための処置
- 若干保守的
- 上書きは発生し得るけど「まだコミットされてはいない」ので問題はない
コミット破棄の図 (論文のFigure8):

要約:
- コミットで必要なのが過半数
- 次のvoteでリーダーになるのが必要なのが過半数
- 必ず一つのサーバが両方に含まれるので、コミットされたものが喪失することはない、という論点
! 以下の二つが満たされる:
- リーダー完全性:
- ログエントリがコミットされたら、それは、その後の全ての期間のログに含まれている
- ステートマシン安全性:
- ログエントリをステートマシンに適用したら、他のサーバは異なるエントリを同じインデックスで適用することはできない
サーバを止めずにクラスタの構成(メンバーリスト)を更新するにはどうすれば良いか?
- 構成を特別なログに保存する
- old => old/new => new、と遷移する
- old/newでは、old設定とnew設定の、それぞれで過半数の得票を獲得する必要がある
- 特に難しいことはない
- 通常のレプリケーションプロセスと同様
- RPCの再送があったとしてもRaftのRPCは
idempotentだから大丈夫
boardcatTime << electionTimeout << MTBFが満たせないと可用性が損なわれる
ログの肥大化を防ぐにはどうすれば良いか?
スナップショットを使う:
- 各サーバでそれぞれ独立して、
- コミット地点のステートマシーンをスナップショットとして保存
- その地点以前のログは破棄
- リーダーへのリダイレクト
- 線形化可能性
- 他には...
余裕があれば 9.3 を読んで軽く書く
Raftは実用的な分散合意アルゴリズムが備えるべき性質を保持しているか?
- 安全性の保証:
- コミットされた結果しか返さない and ログおよびステートマシンの一貫性の話
- 高可用性:
- 過半数が生きていれば大丈夫
- リーダー選出
- ログエントリコミット
- ユーザへの応答
- 過半数が生きていれば大丈夫
- タイミング問題は整合性(一貫性)には影響を与えない:
- 一貫性が絡む、かつ、実時間に依存するような処理はない
- タイムアウトがあるので、(値次第で)可用性は損なわれる可能性あり
TODO:
- 理解可能性を強調しているだけあって分かりやすくはあった
- raftに限った話ではないかもしれないけど読み込みでスケールしなさそう (素直な実装 and 単一ステートマシンなら)
- リーダーは一人のみ
- 単純にサーバ数を増やすと、RPCが増える (heartbeatだけならそこまでコスト高でもない?)
- リードでもRPC推奨 (リーダになった直後にnoopとかも関連。雑多な話題の節に含める?)
- goraftのREADMEを見ると5〜9台くらいが適切なクラスタサイズ、的なことが書いてある
- (四台以上同時に死ぬことなんて普通ないでしょ?)
- 性能は悪くはなさそう (RPC一回)
- 単体だと評価が難しいので、他の類似アルゴリズムもみてみたい





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
私も Raft に興味があったので興味深く拝見させていただきました。
アルゴリズムの概要を簡単に知ることができて良かったです。
ただ、'condidate' というのは 'candidate' のタイポじゃないかというの気になっています。
もし私の理解不足による勘違いでしたらごめんなさい。